Flare-On 12 Challenge 9 Writeup - 10000
Bag of Tricks: IDA, Python, Resource Hacker, B.Sc, CyberChef
Challenge 9
Recon
The last challenge is opened with a single exe file, 10000.exe, 1GB(!). Because the huge size, I first opened it in ResourceHacker to see if it has any large resources, no way IDA can digest a 1GB .text section.
Finding the Resources
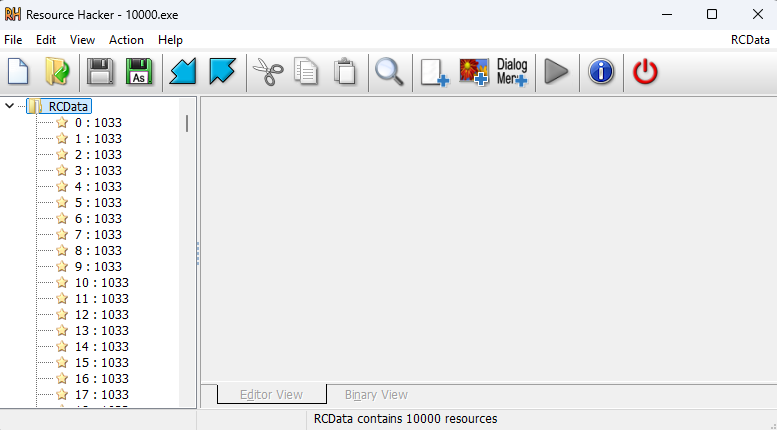
As expected, the large sizing is resource-based. There are 10,000 resources that appear to be encoded/encrypted MZs (the MZ isn’t right, also the other headers).
Looking at Strings/Imports
The program definitely loads the resources into memory at some point, resolving all their imports using LoadLibrary/GetProcAddress.
Reversing the Binary
Opening in IDA was rapid, expected because the .text section isn’t actually that big. The binary itself is kind of big, IDA recognizes 4000+ procedures but I didn’t see any huge, bloated ones like the ones from challenges 5/7/8.
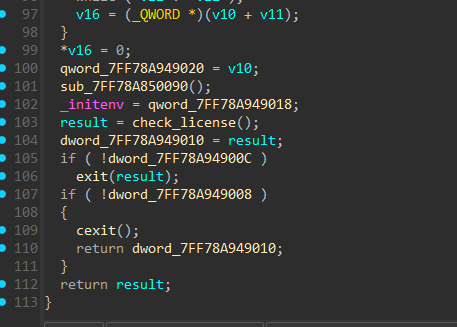
main seems to be simple enough, the only logic bearing function I see called from it is this function, I later named check_license.
License.bin Verification
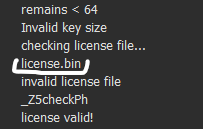
When running the binary, we get a license check and a quick invalid
1
2
3
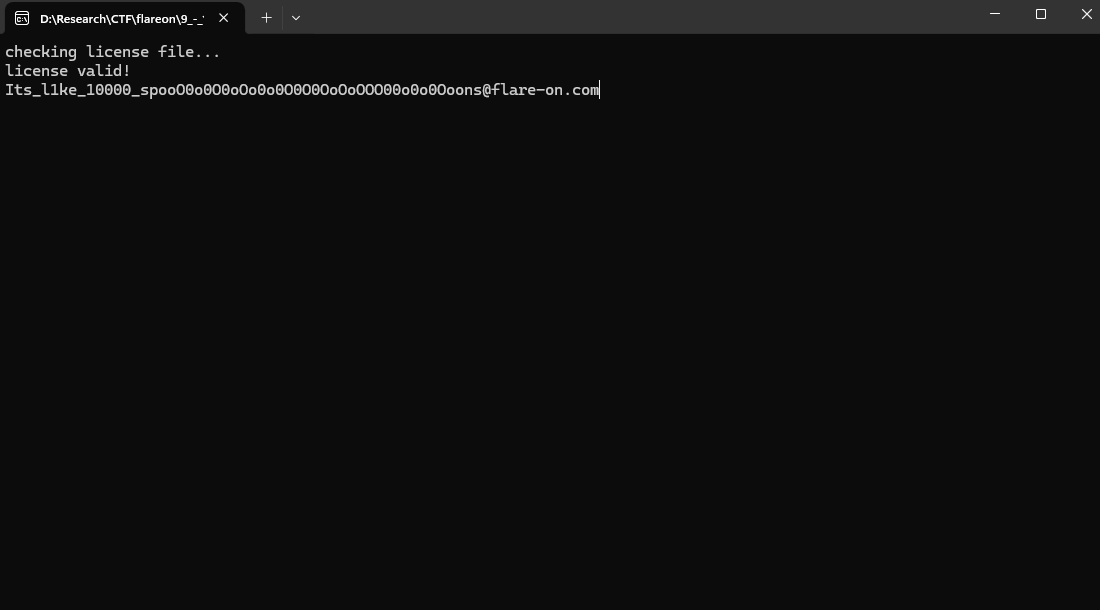
CTF\flareon\9_-_10000> ./10000.exe
checking license file...
invalid license file
The program ran so quickly it was weird, maybe if I place a license.bin in it’s folder it will be quicker. No, maybe there are some requirements on the license.bin before any resource handling happens, I’ll dive into check_license
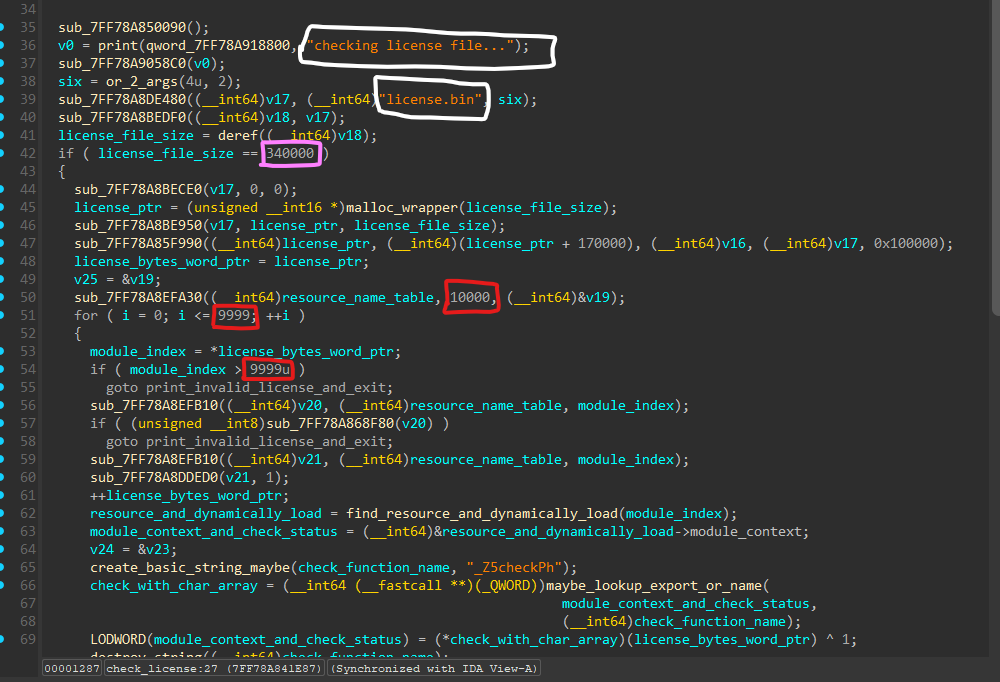
This function is simple enough when debugging it, so naming everything was simple. As expected from earlier, we are checking the license.bin from the current directory, but we first check if it’s size is 340000 bytes, when creating a \x00*340000 file named license.bin the program takes a long while before printing the invalid license file, so we probably got to the resource part.
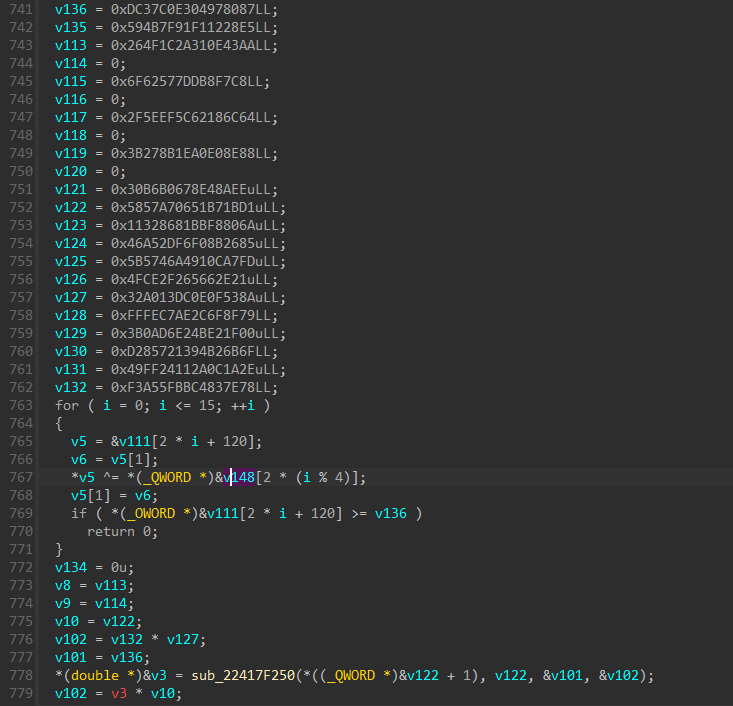
From the screenshot I pasted we can see 10,000 seem t be the number of times the for loop is ran. even more, the loop goes as follows:
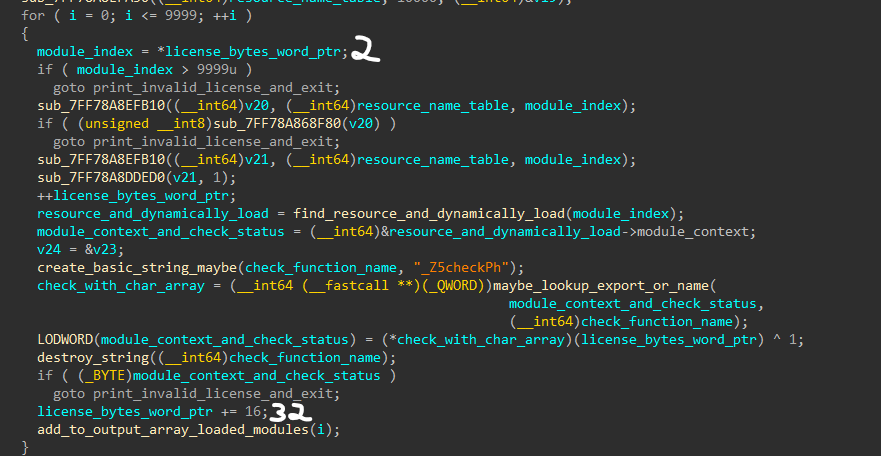
For every iteration, we take the current 2 bytes (word) from license.bin and use them to resolve something only after checking it’s between 0 and 9999 (probably load the resource) and call some check function with the later 32 bytes of license.bin, then continuing to the next 34 bytes, times 10,000 iterations (or 34*10000=340000 bytes).
This makes a lot of sense, given that _Z5checkPh is actually check(unsigned char*) demangled and is fed with a byte array.
Dynamic Loading of Resources
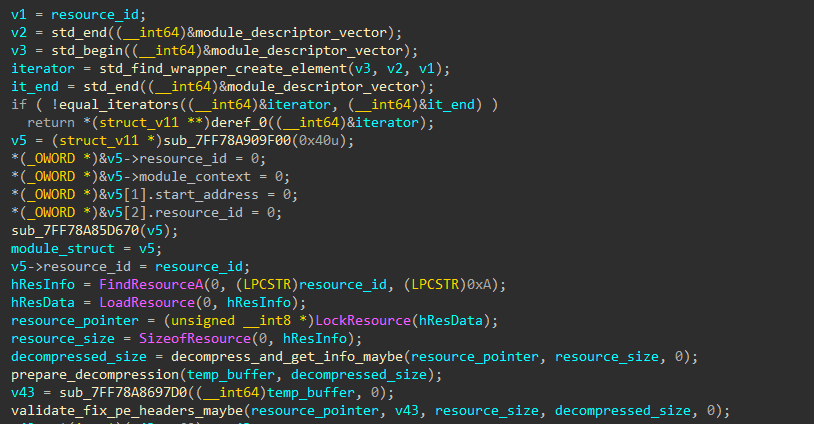
Let’s go into find_resource_and_dynamically_load, and check if our hypothesis is correct, and it does load each resource into memory and resolve it’s check function.
Part 1 - Mapping the Resource to Program Memory
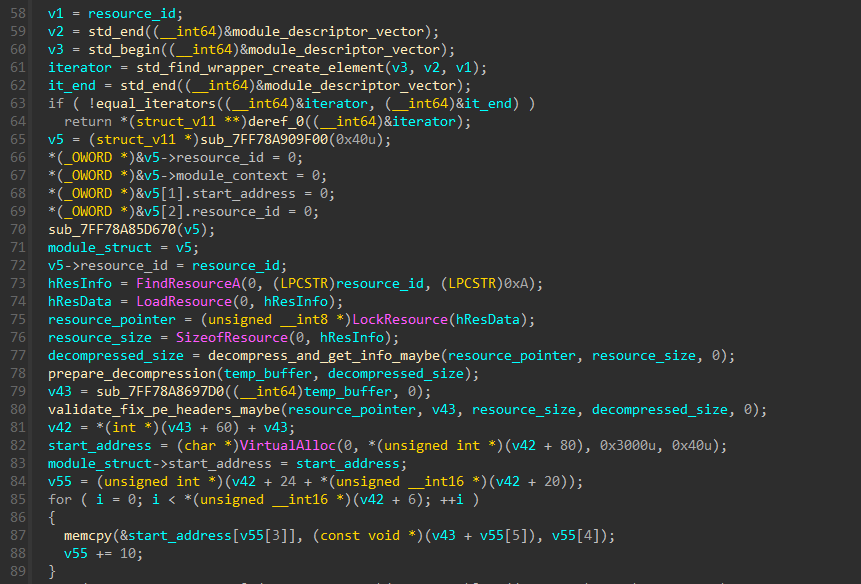
Using WinAPI to resolving the current resource from the function params and mapping it to memory via VirtualAlloc, and copying each section with a memcpy loop. Also, a module_struct is defined, that holds the following:
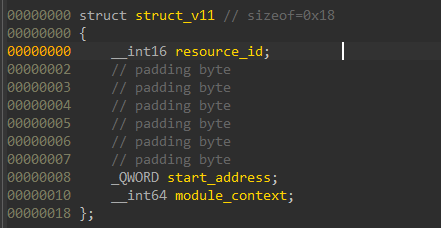
start_address is the address in program memory, while module_context is used to resolve function addresses in the modules with maybe_lookup_export_or_name(module_context, mangled_function_name). module_context holds function addresses, it is initialized later on in this function
One more part I left out is the decompression of the resource data before loading it into memory via decompress_and_get_info_maybe, I didn’t get into the implementation because I realized I can just write an IDA Python script (like my challenge 8 writeup) to repeatedly call this function and extract all 10,000 decompressed resources and dump them into a folder.
Part 2 - Resolving Imports and Recursively Loading Resource Dependencies
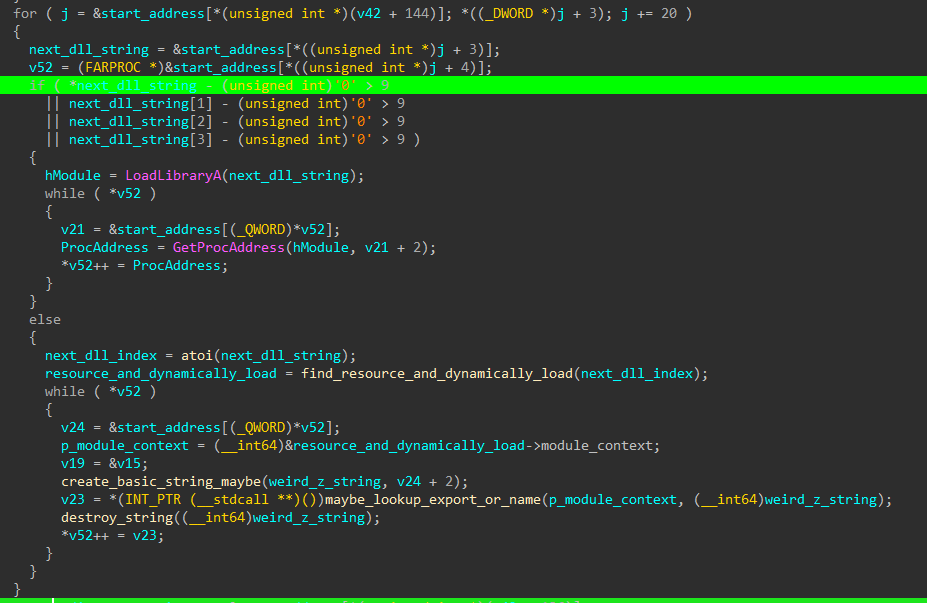
Ignore the horrible IDA disabled breakpoint color again and look that if the first 4 chars of the next dll’s name are digits, the program does not do a classic
1
2
3
4
5
for module in modules:
LoadLibrary(module.name)
while(*funcs):
save(GetProcAddress(*funcs))
funcs++
But a recursive call to itself, with the resource id of the dependency!
This is huge, literally. This means that in every iteration of the 10k, the program loads every resource dependency of the current
module_index = word ptr license[i]before callingcheckofmodule_index. From my previous CTF knowledge, I’ll make a bold assumption that we are not supposed to run this program, even with the rightlicense.binbecause the DLLs probably have 100s of dependencies and will never finish. Instead, we’ll need to generate a workinglicense.bin, validate it ourselves (hard, because there are so many dependencies) and manually setripto decrypt the flag with ourlicense.binbytes incheck_license.
Part 3 - Initializing module_context and Fixing Relocations
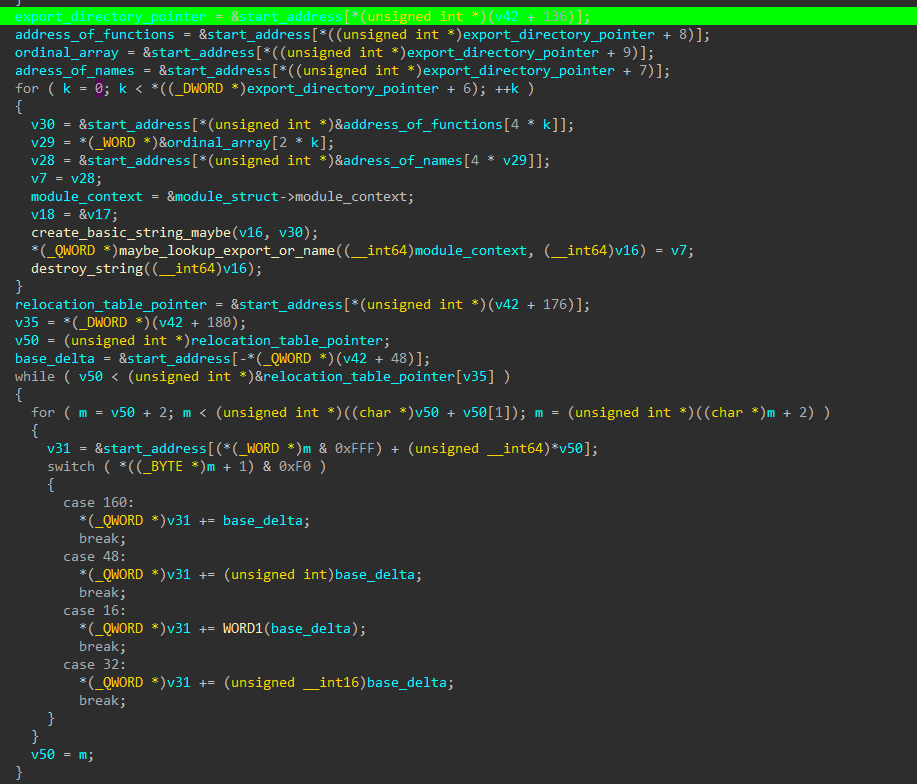
In this stage the program fixes all relocations and and prepares the DLL for execution (we need it to be right for the check(unsigned char *) to work nicely. It also initializes module_context with the export functions for later use.
Part 4 - Calling Entry Point with global_output_array and Adding to Loaded Module Vector
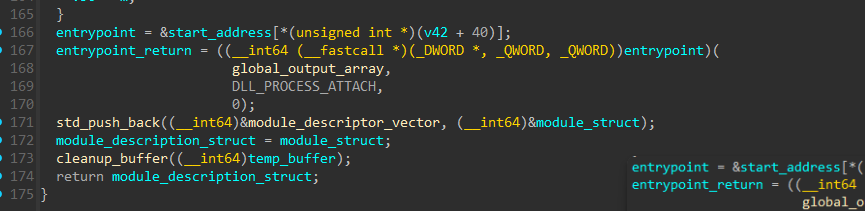
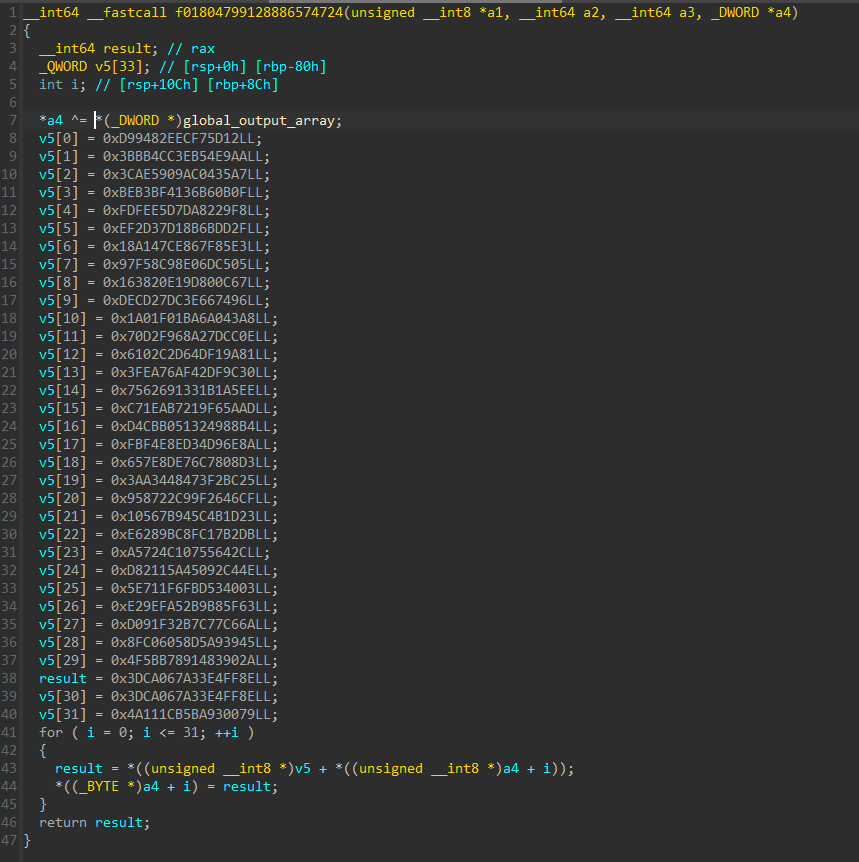
The last part is calling the loaded module’s entrypoint with the global_output_array and doing module_descriptor_vecotr.push_back(current_module_struct) before returning. We’ll get into more detail about global_output_array and module_descriptor_vector in the next section.
Let’s observe the entrypoint of an example DLL
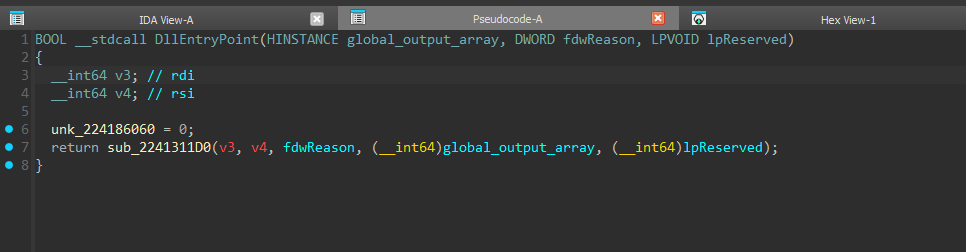
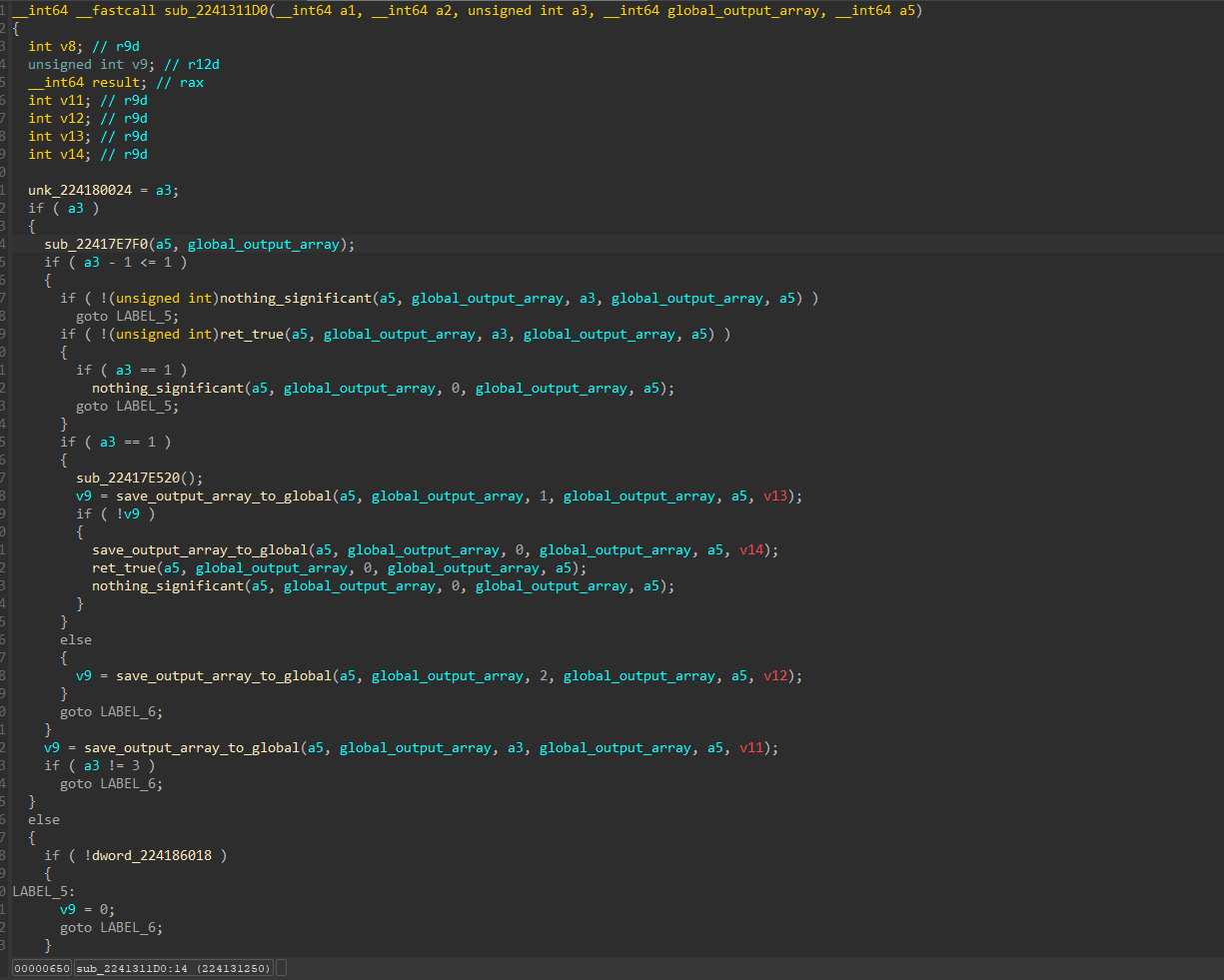

It basically takes in the global_output_array and saves it to a global, for later use
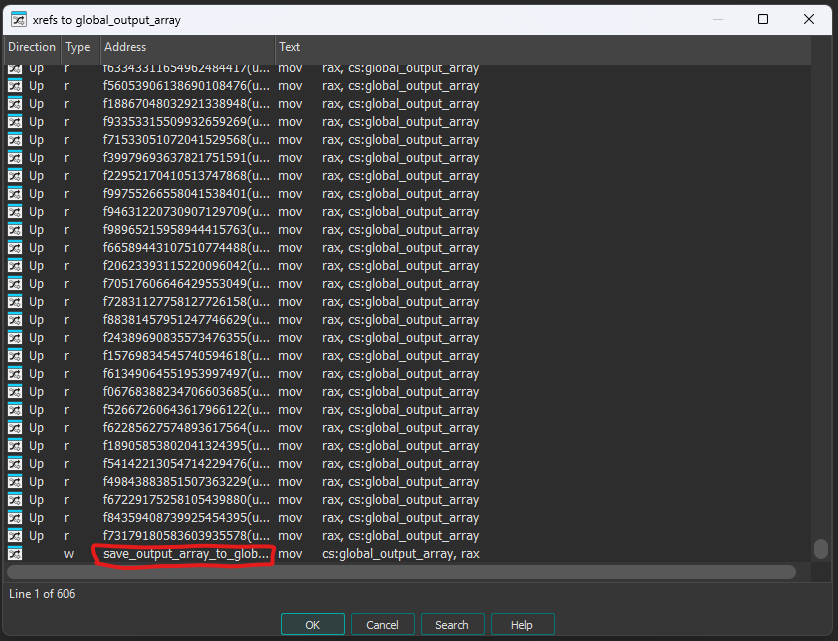
It has a lot of xrefs, from subfunctions of check we’ll get into later, and current saving function.
Understanding the Win-Condition
Okay, nice, we have a lot of information and able to make some assumptions, but this time around it won’t be needed, because we have one more major function to get into, that will tell us exactly what the win condition is.
license.bin Format
Before diving into the last function, let’s summarize the format of license.bin as we currently know.
1
2
3
4
5
6
7
struct resource_information // sizeof() = 34 bytes
{
word resource_id; // 2 bytes
unsigned char[32] check_input; // 32 bytes
}
resource_information license_file_data[10000]; // 10000*34=340000 bytes
add_to_output_array_loaded_modules
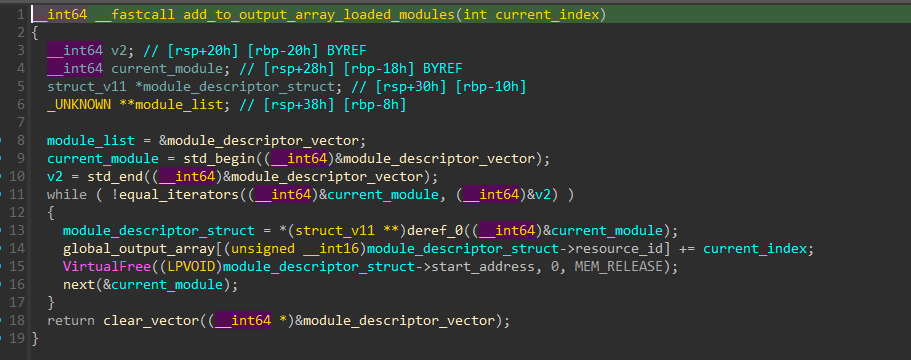
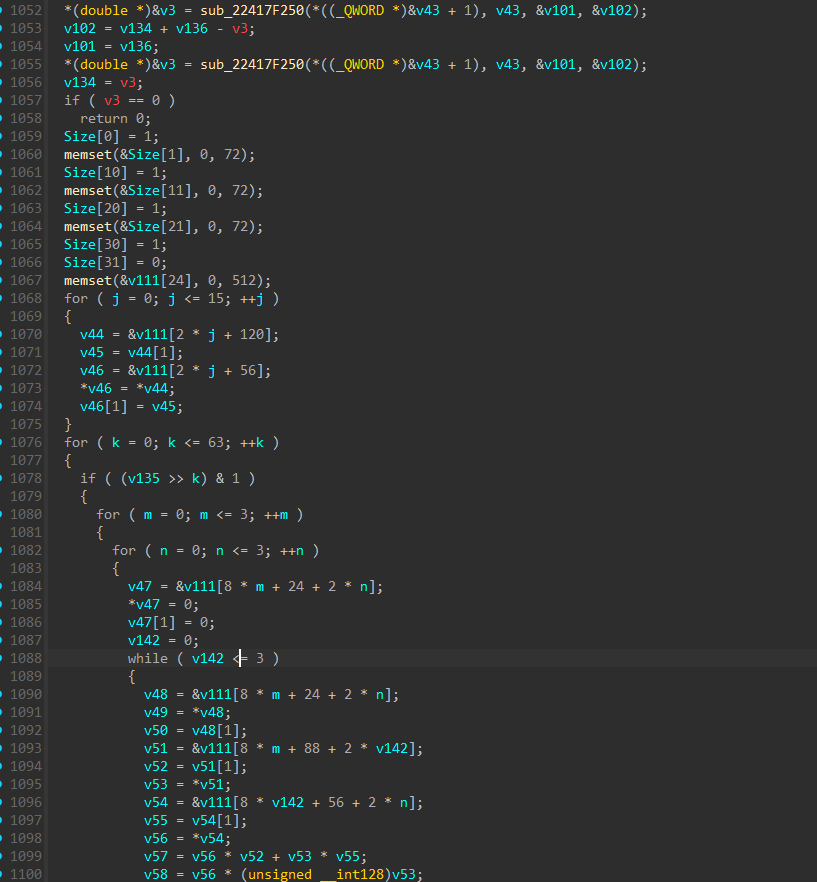
This function is rather short and simple, but holds enormous value in our path to the flag. It first takes in the current index of the loop and loops over all loaded resources in this current iterations (license[i]->resource_id + all of it’s resource dependencies) and adds current_index to an array at the index of each modules resource_id.
1
2
3
for module in current_module_dependencies:
global_output_array[module->resource_id] += current_index
current_module_dependencies.empty()
From this we can make a few, very important conclusions.
❗
global_output_arrayis an array of sums. The sum of each index is the sum of all loop indexes the current index (resource id) was a dependency oflicese[i]->resource_id. To set this straight, for every 2 byte chunk ofresource_informationinsidelicense.binwe load a lot of DLLs as dependencies, for each of them (as long as the root one of this iteration) we add the current loop index to the array of sums.
❗
module_descriptor_vectorAs long with all dynamic memory allocations are cleared from iteration to iteration, so the sum ofglobal_output_array[resource_id]is only the iterationsresource_idplayed a part in, and not some seniority index inlicense.bin.
Passing 10,000 check Functions
Let me take you back to check_license and remind you that even if a single’s license[i]->resource_id’s check(unsigned char*) fails we exit the entire program with a fail. That explains the ~1 minute it took for my program to fail when I gave it a zero license in the right size, it only ran 1(!) iteration and it took it this much time (and I have a beefy machine).

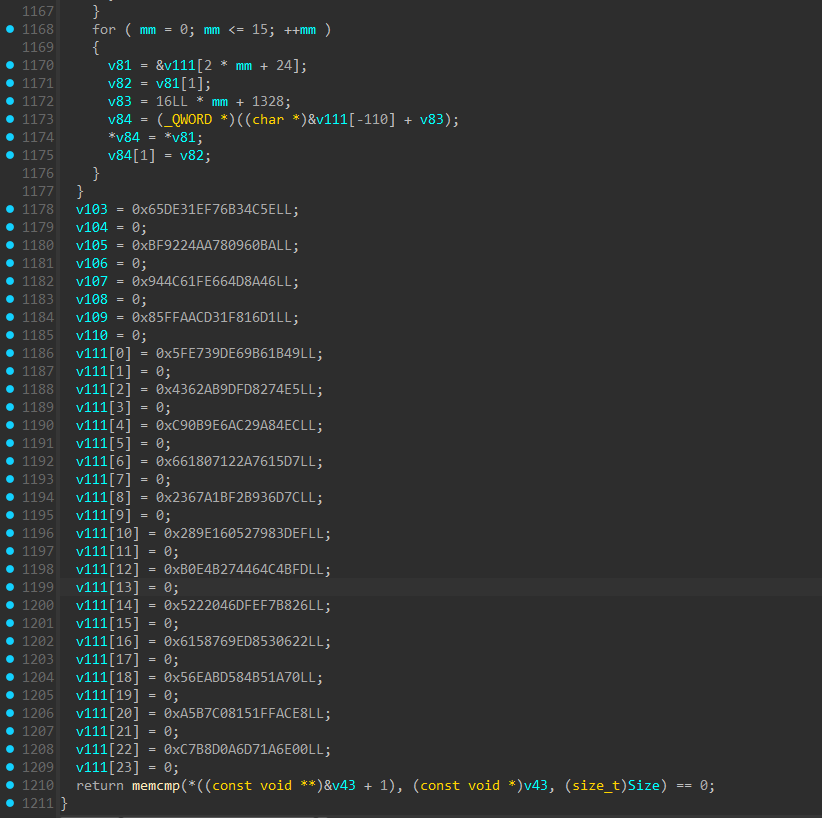
After the loop, only if it succeeds and passes 10k checks (perfect license) it compares the sum array from earlier to a hardcoded one, 10,000 DWORDs = 40,000 bytes and only if correct, we print the flag, that is generated from the actual license.bin bytes.
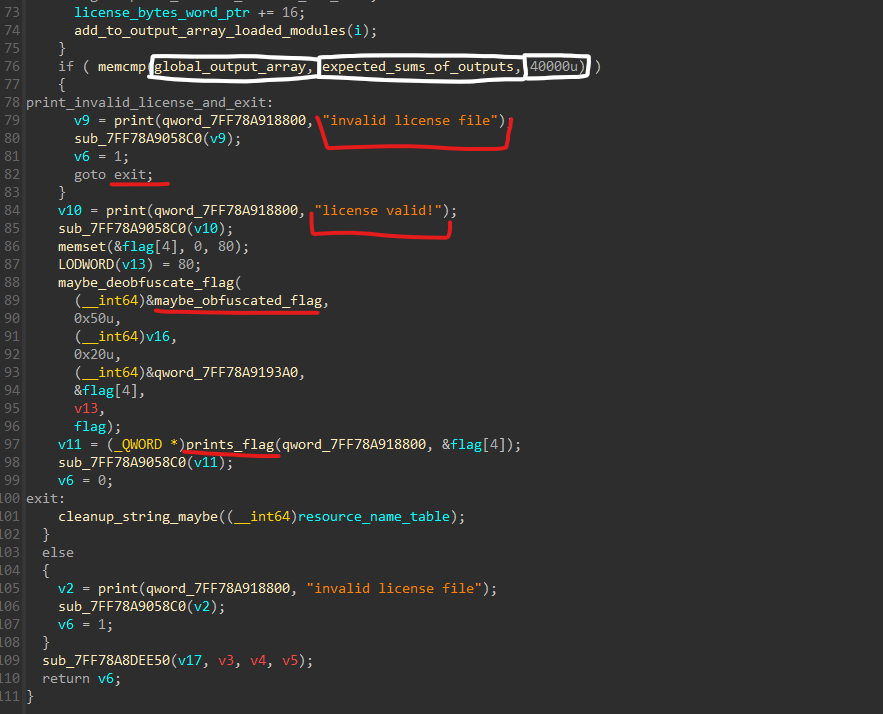
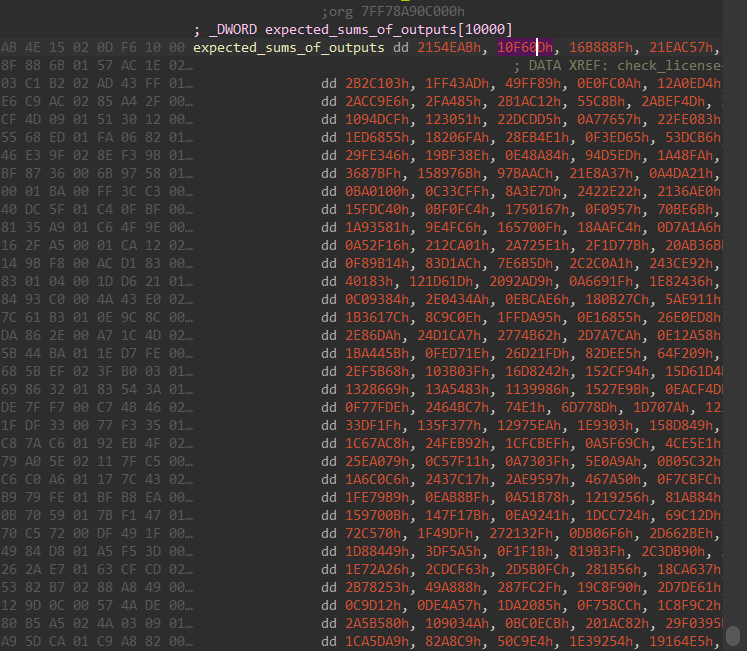
Path-To-Win and Current Conclusions
Path to win:
- Find the right DLL order
- Because
global_output_arraychanges a lot in each iteration (I parsed the example DLL and it had thousands of resource dependencies) we’ll need to create 10,000 different state-arrays ofglobal_output_arrayand feed eachcheckwith the right one from the order we found in step 1 - Succeed in reversing
check - Automate the process and for each check give the right state (based on order found in step 1 and state from step 2) and get the
32*10000license bytes missing - Generate a final license file, with the right order as the first 2 bytes of every
resource_informationand the 32 bytes of the check reverse. - Debug
check_licenseand afterlicense.binis read before the loop jump straight to the flag decryption process. - Profit.
❗We can separate this into two, completely orthogonal tasks. Finding the right DLL order is a closure graph problem I will get into later and succeeding in reversing the process of a given check function (assuming we have the right
global_output_arraystate). ❗After succeeding in these tasks, we can combine the two together and create the finallicensefile.
Task 1 - Finding the DLL Order
Explaining the Problem
❗The problem is an inverse dependency sum. The inputs are a directed graph of resource dependencies (input 1) and the final sums of the dependencies based on the order of the right permutation (we need to find the right permutation of 10k resources so their sums will equal). By solving this inverse problem we can get the right permutation.
The sums are produced by adding each resource’s position index to every resource in it’s dependency closure.
Solving Steps
- Parse and construct the graph from the imports (I extracted them into a JSON). From the JSON we can build the strongly connected components that make the actual directed graph. We will use Kosaraju’s algorithm for the graph.
- Compute the transitive closures of each module.
- To go in reverse and reconstruct the right permutation we will use a greedy reverse peel algorithm that will pick feasible modules for the current position (closure sum >= position).
Example
Given the simple graph below, I will calculate their closures and then sums based on an order I picked
1
2
3
4
5
6
7
8
9
10
11
dll_0 -> dll_2 -> dll_4
dll_1 -> dll_2
dll_3 -> dll_1
dll_5
closure(dll_0) = {0,2,4}
closure(dll_1) = {1,2,4}
closure(dll_2) = {2,4}
closure(dll_3) = {3,1,2,4}
closure(dll_4) = {4}
closure(dll_5) = {5}
Now to calculate the sum of a given module we just some the position in the permutation of all closures:
1
E[4] = pos(0)+pos(1)+pos(2)+pos(3)+pos(4)
Resources
https://en.wikipedia.org/wiki/Kosaraju%27s_algorithm https://en.wikipedia.org/wiki/Tarjan%27s_strongly_connected_components_algorithm
Simpler Explanation
We need to find the right permutation of resource_ids to then when computing the sums of all their dependencies equal expected_sums_of_outputs. To solve this problem we are using known graph theory algorithms and giving them our directed graph of dependencies.
Extracting the Resources
Finally some assembly. To get the decoded resources all into a folder I wrote almost an exact IDA Python script to the one from my challenge 8 writeup.
The script sets rip to be the start of find_resource_and_dynamically_load after setting the right resource_id and just after the decompression reads and extracts the whole memory mapped resource to a file.
1
2
3
4
5
6
7
8
for i in range(10000):
idc.set_reg_value(i, "RCX")
idc.set_reg_value(START_OF_FUNC, "RIP")
# Setting a callback after the decompression
# Continue Execution
current_outfile.write(retrive_resource_from_memory(resource_pointer, resource_size))
Terrific!
Generating the Import Dependency JSON
Used Python’s pefile to parse each file and dump it’s resource imports to a large JSON.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
from typing import Dict, List, Set
from multiprocessing import Pool, cpu_count
import pefile
def extract_id_from_filename(fn: str):
m = re.search(r'(\d{1,5})', os.path.basename(fn))
return int(m.group(1)) if m else None
def parse_imports_worker(args):
mid, path, N = args
imports = set()
pe = pefile.PE(path)
if hasattr(pe, 'DIRECTORY_ENTRY_IMPORT') and pe.DIRECTORY_ENTRY_IMPORT:
for entry in pe.DIRECTORY_ENTRY_IMPORT:
try:
name = entry.dll.decode(errors='ignore').split('.')[0]
except Exception:
continue
if name.isdigit():
v = int(name)
if 0 <= v < N:
imports.add(v)
pe.close()
return (mid, sorted(imports))
After that, just dumping to the json.
1
2
3
4
5
6
7
8
9
10
11
12
{
"...",
"2342":
{
"fp": [426496, 1760058906],
"imports":
[
50, 89, 90, 97, 106, 176, 181, 192, 230, 242, 250, 251, 256, 271, 280, 284, 285, 286, 310, 325, 327, 334, 338, 364, 390, 393, 418, 423, 434, 441, 462, 474, 479, 516, 522, 547, 554, 571, 606, 638, 644, 658, 678, ....
]
},
"..."
}
Dumping expected_sums_of_outputs to a file
Went to the file offset in 010 Editor and just copied using Ctrl Shift C into a new hex file.
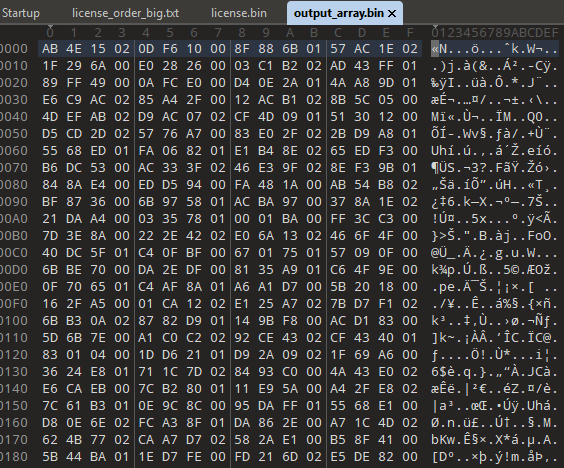
Remember, now they are in little endian.
Scripting the Solution
Below is the final solution script that solves the graph problem in the steps I explained above, it takes in the import.json we generated with the expected_sums_of_outputs we dumped. This is the snippet that calculates the closure array array and the final permutation and checks it against expected_sums_of_outputs (because I already have the right DLL order).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
import sys, json, struct, time
from collections import deque
def load_imports(path):
with open(path, "r") as f:
j = json.load(f)
N = 0
for k in j.keys():
N = max(N, int(k) + 1)
g = [[] for _ in range(N)]
for k, v in j.items():
idx = int(k)
if isinstance(v, dict) and "imports" in v:
arr = v["imports"]
elif isinstance(v, list):
arr = v
else:
arr = []
g[idx] = [int(x) for x in arr if isinstance(x, int)]
return g
def load_expected(path):
vals = []
with open(path, "rb") as f:
while True:
b = f.read(4)
if not b:
break
vals.append(struct.unpack("<I", b)[0])
return vals
def load_license_out(path):
vals = []
with open(path, "rb") as f:
while True:
b = f.read(2)
if not b:
break
vals.append(struct.unpack("<H", b)[0])
return vals
def compute_sccs(g):
N = len(g)
gr = [[] for _ in range(N)]
for u in range(N):
for v in g[u]:
if 0 <= v < N:
gr[v].append(u)
visited = [False]*N
order = []
# DFS
for i in range(N):
if visited[i]: continue
stack = [(i, 0)]
while stack:
u, it = stack[-1]
if not visited[u]:
visited[u] = True
children = g[u]
if it < len(children):
stack[-1] = (u, it+1)
v = children[it]
if 0 <= v < N and not visited[v]:
stack.append((v, 0))
else:
order.append(u)
stack.pop()
comp = [-1]*N
compcnt = 0
for u in reversed(order):
if comp[u] != -1: continue
stack = [u]
comp[u] = compcnt
while stack:
x = stack.pop()
for y in gr[x]:
if comp[y] == -1:
comp[y] = compcnt
stack.append(y)
compcnt += 1
return comp, compcnt
def build_condensed(comp, compcnt, g):
comp_nodes = [[] for _ in range(compcnt)]
for i,c in enumerate(comp):
comp_nodes[c].append(i)
cdag = [[] for _ in range(compcnt)]
for u in range(len(g)):
cu = comp[u]
for v in g[u]:
if 0 <= v < len(g):
cv = comp[v]
if cu != cv:
cdag[cu].append(cv)
for i in range(compcnt):
cdag[i] = sorted(set(cdag[i]))
return comp_nodes, cdag
def topo_postorder(cdag):
C = len(cdag)
visited = [False]*C
topo = []
for i in range(C):
if visited[i]: continue
stack = [(i,0)]
while stack:
u,it = stack[-1]
if not visited[u]:
visited[u] = True
if it < len(cdag[u]):
stack[-1] = (u, it+1)
v = cdag[u][it]
if not visited[v]:
stack.append((v,0))
else:
topo.append(u)
stack.pop()
return topo
def bit_iter(bitmask):
while bitmask:
lsb = bitmask & -bitmask
idx = (lsb.bit_length() - 1)
yield idx
bitmask ^= lsb
def compute_reachability_bitsets(cdag, topo):
C = len(cdag)
reach = [0]*C
for u in topo:
mask = 0
for v in cdag[u]:
mask |= (1 << v)
mask |= reach[v]
reach[u] = mask
return reach
def expand_closures(N, comp, comp_nodes, reach):
# foreach node make sorted list S[r] of reachable original nodes
S = [[] for _ in range(N)]
for r in range(N):
cr = comp[r]
acc = set()
# include own nodes
for node in comp_nodes[cr]:
acc.add(node)
# include all nodes in reachable components
mask = reach[cr]
for rc in bit_iter(mask):
for node in comp_nodes[rc]:
acc.add(node)
S[r] = sorted(acc)
return S
def simulate_and_compare(S, license_arr, expected_vals):
N = len(expected_vals)
sim = [0]*N
if len(license_arr) < N:
raise ValueError("license_out.bin shorter than expected length")
for i in range(N):
root = license_arr[i]
if root < 0 or root >= len(S):
raise ValueError(f"license entry {i} -> {root} out of range")
for f in S[root]:
sim[f] += i
diffs = []
for idx in range(N):
if sim[idx] != expected_vals[idx]:
diffs.append((idx, expected_vals[idx], sim[idx]))
return sim, diffs
def main():
if len(sys.argv) != 4:
print("Usage: python3 verify_license.py imports_cache.json expected.bin license_out.bin")
return 1
start = time.time()
imports_path = sys.argv[1]
expected_path = sys.argv[2]
license_path = sys.argv[3]
print("Loading imports...")
g = load_imports(imports_path)
N = len(g)
print(f"Nodes N = {N}")
print("Loading expected.bin...")
expected_vals = load_expected(expected_path)
if len(expected_vals) != N:
print(f"Warning: expected.bin length {len(expected_vals)} != N ({N}). Using min length {min(len(expected_vals),N)}.")
expected_vals = expected_vals[:N] + [0]*(N - min(len(expected_vals),N))
print("Loading license_out.bin...")
license_arr = load_license_out(license_path)
print(f"license_out length = {len(license_arr)}")
t0 = time.time()
print("Computing SCCs (Kosaraju)...")
comp, compcnt = compute_sccs(g)
print(f" components: {compcnt} (time {time.time()-t0:.2f}s)")
t1 = time.time()
comp_nodes, cdag = build_condensed(comp, compcnt, g)
topo = topo_postorder(cdag)
print(f" topo size {len(topo)} (took {time.time()-t1:.2f}s)")
t2 = time.time()
reach = compute_reachability_bitsets(cdag, topo)
print(f" computed reachability bitsets (took {time.time()-t2:.2f}s)")
t3 = time.time()
S = expand_closures(N, comp, comp_nodes, reach)
print(f" expanded closures (took {time.time()-t3:.2f}s)")
t4 = time.time()
sim, diffs = simulate_and_compare(S, license_arr, expected_vals)
print(f"Simulation done (took {time.time()-t4:.2f}s). Total time {time.time()-start:.2f}s")
if not diffs:
print("SUCCESS: simulated expected equals expected.bin exactly.")
ssum = sum(sim)
print(f"Checksum sum(sim) = {ssum}")
return 0
else:
print(f"Mismatch: {len(diffs)} indices differ. Showing up to 40 samples:")
for idx, expv, simv in diffs[:40]:
print(f" idx={idx:5d} expected={expv:10d} simulated={simv:10d} diff={simv-expv:+d}")
diffs_sorted = sorted(diffs, key=lambda x: abs(x[2]-x[1]), reverse=True)
print("\nTop 10 largest absolute differences:")
for idx, expv, simv in diffs_sorted[:10]:
print(f" idx={idx:5d} expected={expv:10d} simulated={simv:10d} diff={simv-expv:+d}")
return 2
if __name__ == "__main__":
sys.exit(main())
1
2
3
4
5
6
7
8
9
10
11
12
13
14
/CTF/flareon/9_-_10000$ python3 verify_license.py imports_cache_big.json output_array.bin license_order_big.txt
Loading imports...
Nodes N = 10000
Loading expected.bin...
Loading license_out.bin...
license_out length = 10000
Computing SCCs (Kosaraju)...
components: 10000 (time 0.32s)
topo size 10000 (took 1.63s)
computed reachability bitsets (took 0.50s)
expanded closures (took 21.72s)
Simulation done (took 1.08s). Total time 25.86s
SUCCESS: simulated expected equals expected.bin exactly.
Checksum sum(sim) = 246018992394
This took me so much time, the approach that worked for me is take small example (like the one I gave you above) and debug the algorithm to find bugs.
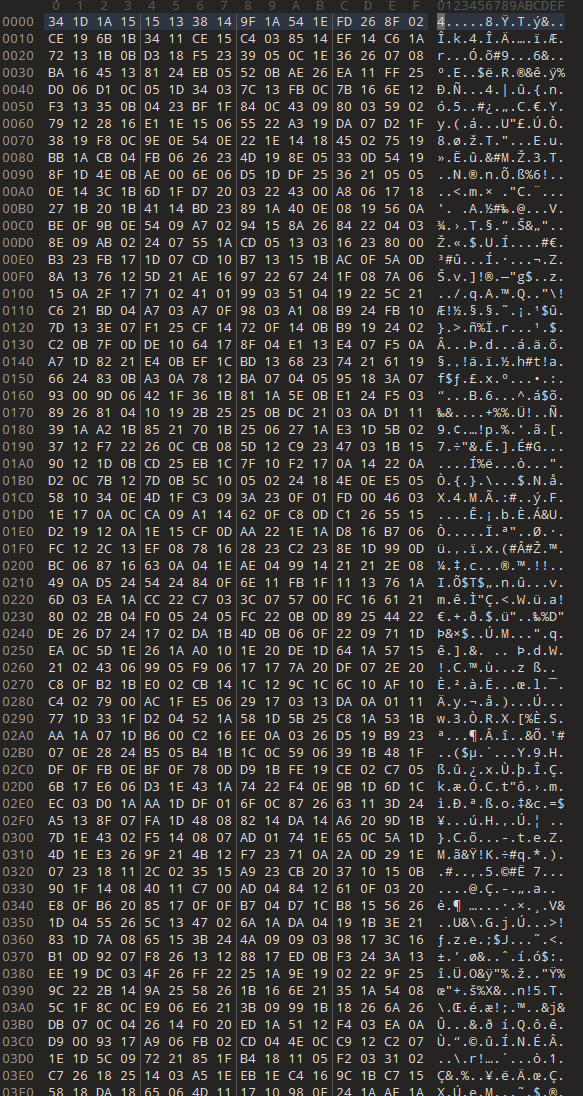
This is not the final license.bin, it is much smaller because it does not include the 32 bytes for every 2 byte resource_id. but this is the order I used to generate the 10k state arrays of 10k dwords for each license[i].
Generating 10,000 States of global_output_array
every iteration global_output_array changes drastically. Meaning check of each module gets an entirely different state depending on the order. Assuming my generated order is correct, license[0]->resource_id is 7476 and it’s state is a full 0 array and resource 4282 is the last resource, thus it’s state is one-off expected_sums_of_outputs (only after it’s check) global_output_array is updated.
To solve this challenge correctly I need to generate a huge state JSON, for every check it’s right global_output_array in the right t_resourceid on the time scale.
I generated a fake
license.binbefore running this script. It had the right order but all 32checkinputs were zeroes.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
import argparse, os, sys, json, re, struct, time
from collections import deque
def load_imports_cache(path):
with open(path, 'r', encoding='utf-8') as f:
raw = json.load(f)
numeric_imports = {}
if isinstance(raw, dict):
for k, v in raw.items():
mid = int(k)
if isinstance(v, list):
numeric_imports[mid] = [int(x) for x in v]
elif isinstance(v, dict) and 'imports' in v and isinstance(v['imports'], list):
numeric_imports[mid] = [int(x) for x in v['imports']]
else:
numeric_imports[mid] = []
return numeric_imports
def read_order_from_license_bin(path, expected_N=None):
data = open(path, 'rb').read()
if expected_N is not None and len(data) == expected_N * 34:
out = []
for i in range(expected_N):
off = i * 34
(rid,) = struct.unpack_from('<H', data, off)
out.append(rid)
return out
if expected_N is not None and len(data) == expected_N * 2:
vals = list(struct.unpack('<' + 'H' * expected_N, data))
return vals
s = data.decode('utf-8', errors='ignore')
toks = re.findall(r'\d+', s)
vals = [int(x) for x in toks]
if expected_N is None:
return vals
else:
if len(vals) >= expected_N:
return vals[:expected_N]
def load_expected(path, N):
b = open(path, 'rb').read()
if len(b) == 4 * N:
return list(struct.unpack('<' + 'I' * N, b))
s = b.decode('utf-8', errors='ignore')
toks = re.findall(r'-?\d+', s)
vals = [int(x) for x in toks]
if len(vals) >= N:
return vals[:N]
def simulate_order_jsonl(adj, order, N, jsonl_path, final_out_path='final_output.bin',
final_only=False, log_interval=1000, flush_every=10):
if len(order) != N:
raise RuntimeError(f"order length {len(order)} != N {N}")
out = [0] * N
visited_mark = [0] * N
mark_id = 1
write_jsonl = (jsonl_path is not None) and (not final_only)
jf = None
if write_jsonl:
jf = open(jsonl_path, 'w', encoding='utf-8')
t0 = time.time()
last_log = t0
steps_since_flush = 0
adj_local = adj
visited_local = visited_mark
for i in range(N):
root = order[i]
if root < 0 or root >= N:
raise RuntimeError(f"invalid resource id {root} at step {i}")
stack = [root]
cur_mark = mark_id
mark_id += 1
while stack:
v = stack.pop()
if visited_local[v] == cur_mark:
continue
visited_local[v] = cur_mark
out[v] += i
for nb in adj_local[v]:
if visited_local[nb] != cur_mark:
stack.append(nb)
if write_jsonl:
obj = {"step": i, "module": root, "global": out}
jf.write(json.dumps(obj, separators=(',',':')))
jf.write('\n')
steps_since_flush += 1
if steps_since_flush >= flush_every:
jf.flush()
os.fsync(jf.fileno())
steps_since_flush = 0
if (i % log_interval) == 0:
now = time.time()
elapsed = now - t0
per_step = elapsed / (i + 1) if i >= 0 else 0.0
rem = per_step * (N - i - 1)
print(f"[.] step={i} elapsed={elapsed:.1f}s per_step={per_step:.6f}s est_remain={rem/60:.1f}min")
if jf:
jf.close()
with open(final_out_path, 'wb') as fo:
chunk = 4096
pack = struct.pack
off = 0
while off < N:
nxt = min(off + chunk, N)
fo.write(pack('<' + 'I' * (nxt - off), *out[off:nxt]))
off = nxt
return out
def main(argv):
ap = argparse.ArgumentParser()
ap.add_argument('--imports', required=True)
grp = ap.add_mutually_exclusive_group(required=True)
grp.add_argument('--license')
ap.add_argument('--jsonl', required=True)
ap.add_argument('--expected', required=True)
ap.add_argument('--final', default='final_output.bin')
ap.add_argument('--log-interval', type=int, default=1000)
args = ap.parse_args(argv)
print("[*] loading imports cache:", args.imports)
numeric_imports = load_imports_cache(args.imports)
N = max(numeric_imports.keys()) + 1
print(f"[*] inferred N = {N}; cache entries = {len(numeric_imports)}")
adj = [[] for _ in range(N)]
for u, neighs in numeric_imports.items():
if 0 <= u < N:
for v in neighs:
if 0 <= v < N:
adj[u].append(v)
order = read_order_from_license_bin(args.license, expected_N=N)
if len(order) != N:
raise RuntimeError(f"order length {len(order)} != N {N}")
print("[*] starting simulation -> JSONL:", args.jsonl, "; final_out:", args.final,
"; final_only:", args.final_only)
t0 = time.time()
final_out = simulate_order_jsonl(adj, order, N, args.jsonl, final_out_path=args.final,
final_only=args.final_only, log_interval=args.log_interval)
t1 = time.time()
print(f"[*] simulation finished in {t1 - t0:.2f}s; final wrote to {args.final}")
print("[*] validating final output against expected:", args.expected)
expected = load_expected(args.expected, N)
mismatches = []
for i in range(N):
if final_out[i] != expected[i]:
mismatches.append((i, final_out[i], expected[i]))
if len(mismatches) >= 30:
break
if mismatches:
print("[!] FINAL MISMATCHES (first up to 30):")
for idx, r, e in mismatches:
print(f" idx={idx} recon={r} expected={e}")
sys.exit(2)
else:
print("[+] Final output matches expected.bin exactly.")
if __name__ == '__main__':
main(sys.argv[1:])
Huge JSON preview:
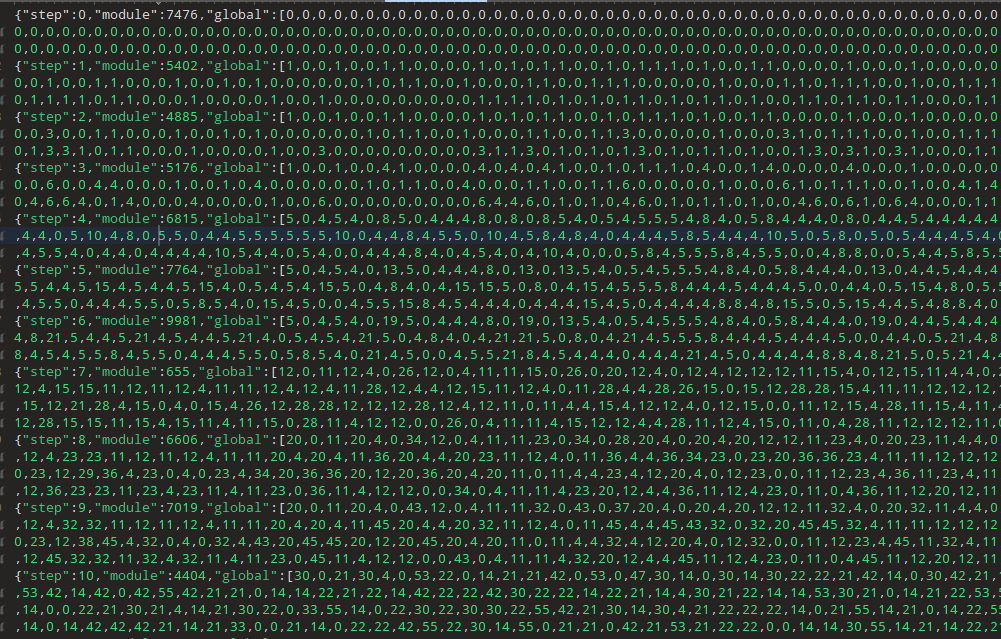
That makes a lot of sense, we can see the first module (7476) gets an empty array as expected and the second one gets an array of 1s and 0s.
Or Does It?
When solving this I didn’t spot this bug, there is an off-by-one here, and it cost me some debugging and hair pulling. Actually "global" of "step":n should be "step":n+1’s "global". I hot-fixed this in the final script to save myself generating a new huge JSONL object.
Now that we have the right order and all the states, we are ready to continue to the simpler assembly task.
Task 2 - Reversing check
Reversing check manually
check starts off with a longs series of sub-function calls we will get into later, but for now remember they have a few distinct types and they depend on the global_output_array[resource_id] from the current state. Also, the reason the modules have so many sub-module dependencies is because all the purple f’s are imported from other modules, and thus dependent on global_output_array[import_from] but from state[resource_id] and that is why the 10,000*10,000 array of states is required.
After the f chain we have a very long series of operations that do 4 by 4 matrix multiplications and compare those to a const hardcoded value for each different check.
We can separate each check to multiple different phases that have different parameters that mutate their, and thus the final boolean result.
- f function series (each function is one of a few types), mutate an in-memory variable based on the
global_output_arrayof the current state (dependent on the order from task 1)- Every imported f is dependent on
global_output_array[imported_from] - Every local f is dependent on
global_output_array[resource_id]
- Every imported f is dependent on
- Matrix building, we take the value from the series of f and xor it against hardcoded values. dependent only on f series result
- Matrix manipulation - series of manipulations, then feeding into memcmp, dependent only on the previous phase
❗If the matrix multiplication + f functions are reversible (knowing the state) we can reverse the entire process after extracting the constants from each binary
fFunction Types, Python Implementation
Now I’ll get into the internals of each f function. There are 3 distinct types of f function, B/C/D and to diff between them I used the number of local variables from the function prolog
sub rsp, X
Makes room on the stack for all local variables this function uses.
I’ll paste in the Python implementation for each function type, when we have the forward Python implementation, making the reverse is straight-forward.
Class B
Frame size = 0x110
That basically does:
1
2
3
4
5
6
7
8
9
10
11
12
def b(input_bytes, global_output_array_from_state_at_resource_id):
if len(input_bytes) != 32:
raise ValueError("licData must be exactly 32 bytes")
temp = bytearray(input_bytes)
# XOR first 4 bytes
v = int.from_bytes(temp[0:4], 'little') ^ (global_output_array_from_state_at_resource_id & 0xFFFFFFFF)
temp[0:4] = v.to_bytes(4, 'little')
out = bytearray(32)
for i in range(32):
out[i] = self.SUB_TABLE[temp[i]]
return bytes(out)
Class C
Frame size = 0xc0
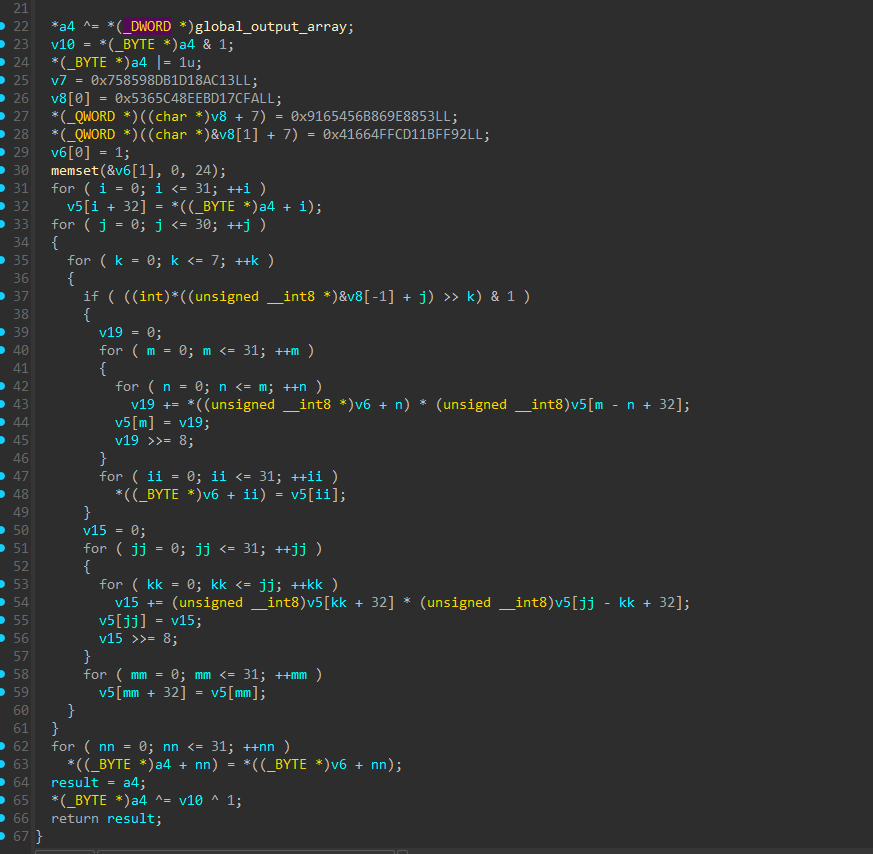
And in python:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
def c(self, input_bytes: bytes, global_output_array_from_state_at_resource_id: int) -> bytes:
assert len(input_bytes) == 32
mem = bytearray(input_bytes)
# XOR low dword with glob value (write full dword)
orig_dword = int.from_bytes(mem[0:4], "little")
new_dword = (orig_dword ^ (global_output_array_from_state_at_resource_id & 0xFFFFFFFF)) & 0xFFFFFFFF
mem[0:4] = new_dword.to_bytes(4, "little")
# var_31 = low byte & 1 (after XOR)
var_31 = mem[0] & 1
# write low byte = low_byte | 1 (assembly writes one byte only)
mem[0] = mem[0] | 1
# base (32-byte little-endian int)
base = FuncC.le_bytes_to_int(bytes(mem))
acc = 1
# build exponent integer from first 31 bytes of locBuf (0..0x1E)
exponent_int = 0
for byte_index in range(0x1F): # 31 bytes = 248 bits
exponent_int |= self.LOCBUF[byte_index] << (8 * byte_index)
# iterate bits little-endian (low bit first)
for bit_index in range(0x1F * 8): # 248 bits
bit = (exponent_int >> bit_index) & 1
if bit:
acc = (acc * base) % self.MOD
base = (base * base) % self.MOD
# write acc back (32 bytes)
acc_bytes = FuncC.int_to_le_bytes(acc, self.LIC_SIZE)
result = bytearray(acc_bytes)
# final low byte tweak: result[0] = (result[0] ^ var_31) ^ 1
result[0] = ((result[0] ^ var_31) ^ 1) & 0xFF
return bytes(result)
Class D
Frame size = 0x50
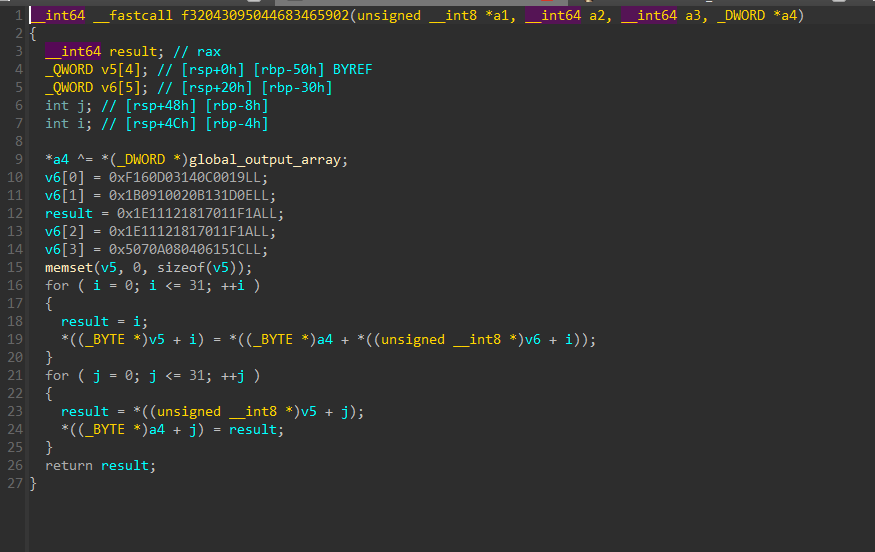
And Python implementation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
def d(self, input_bytes: bytes, global_output_array_from_state_at_resource_id: Union[bytes, int]) -> bytes:
if not isinstance(input_bytes, (bytes, bytearray)) or len(input_bytes) != 32:
raise ValueError("licData must be 32 bytes")
glob_val = global_output_array_from_state_at_resource_id
# Validate table is a 0..31 permutation (same checks as reverse)
if not isinstance(self.table, (bytes, bytearray)) or len(self.table) != 32:
raise ValueError("table must be 32 bytes")
seen = [False] * 32
for i, t in enumerate(self.table):
if t < 0 or t >= 32:
raise ValueError(f"table value out of range: {t} at index {i}")
if seen[t]:
raise ValueError(f"table is not a permutation (duplicate {t})")
seen[t] = True
if not all(seen):
raise ValueError("table is not a full permutation of 0..31")
# Step 1: XOR low dword with glob_val
temp = bytearray(input_bytes)
low32 = int.from_bytes(temp[0:4], 'little') ^ glob_val
temp[0:4] = (low32 & 0xFFFFFFFF).to_bytes(4, 'little')
# Step 2: forward permutation: out[i] = temp[ table[i] ]
out = bytearray(32)
for i in range(32):
idx = self.table[i]
out[i] = temp[idx]
return bytes(out)
Matrix Manipulation Automating
The below code snippet takes in all hardcoded constants from the PE parsing script and implements the matrix multiplications from the check functions.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
import os
import json
import struct
from math import gcd
from tqdm import tqdm
def matmul_mod(A, B, p):
"""Multiply two square matrices A,B modulo p."""
n = len(A)
C = [[0]*n for _ in range(n)]
# standard i-k-j ordering (good locality for small n=4)
for i in range(n):
for k in range(n):
aik = A[i][k]
for j in range(n):
C[i][j] = (C[i][j] + aik * B[k][j]) % p
return C
def matpow_mod(A, exponent, p):
"""Fast exponentiation of matrix A to power exponent modulo p."""
n = len(A)
result = [[1 if i == j else 0 for j in range(n)] for i in range(n)]
base = [row[:] for row in A]
e = exponent
while e:
if e & 1:
result = matmul_mod(result, base, p)
base = matmul_mod(base, base, p)
e >>= 1
return result
def reconstruct_input(modulus, exponent, target_vals, matrix_consts):
"""
Given modulus p, exponent e, target bytes T (flattened 4x4) and matrix
M (flattened 4x4) return 4 64-bit little-endian integers packed as bytes
if consistent with M' = T^(e^-1) mod p and M' xor M is same across rows.
"""
p = modulus
# group order used in original: (p^4-1)*(p^4-p)*(p^4-p^2)*(p^4-p^3)
p4 = p**4
group_order = (p4 - 1) * (p4 - p) * (p4 - p**2) * (p4 - p**3)
if gcd(exponent, group_order) != 1:
return b''
inv_exp = pow(exponent, -1, group_order)
# convert flat lists to 4x4
T = [target_vals[i*4:(i+1)*4] for i in range(4)]
M = [matrix_consts[i*4:(i+1)*4] for i in range(4)]
M_prime = matpow_mod(T, inv_exp, p)
# input values are per-column XOR of first row
col_inputs = [M_prime[0][c] ^ M[0][c] for c in range(4)]
consistent = all(
(M_prime[r][c] ^ M[r][c]) == col_inputs[c]
for r in range(4) for c in range(4)
)
if not consistent:
# keep quiet in automated runs; caller can detect zero-length result
return b''
# pack each input value as little-endian 8-byte unsigned
return b''.join(struct.pack('<Q', int(v)) for v in col_inputs)
def process_json_dir(input_dir="json_dir", out_dir="check_output"):
"""Iterate over per-DLL JSON files, reconstruct inputs, and write output files."""
os.makedirs(out_dir, exist_ok=True)
files = [f for f in os.listdir(input_dir) if f.endswith('.json')]
for fname in tqdm(files, desc="Processing"):
base = os.path.splitext(fname)[0]
path = os.path.join(input_dir, fname)
with open(path, "r") as fh:
jd = json.load(fh)
f_chain = jd["check"]["consts"]["after_f_chain"]
memcmp = jd["check"]["consts"]["memcmp"]
modulus = int(f_chain[0], 16)
exponent = int(f_chain[1], 16)
matrix_consts = [int(x, 16) for x in f_chain[2:]]
target_vals = [int(x, 16) for x in memcmp]
out = reconstruct_input(modulus, exponent, target_vals, matrix_consts)
with open(os.path.join(out_dir, base + "_check"), "wb") as outfh:
outfh.write(out)
if __name__ == "__main__":
process_json_dir()
Creating Constants JSON from PEs
Now we need to build a huge JSON, basically the integration of all steps from task 2 before the actual integration with the JSON from task 1. We need to combine matrix manipulation logic with PE parsing, generating a huge json of constants a f function, that together with the states json can be used in one final, ugly script to reverse all f checks and generate the license.bin file. Together with the matrix logic from above we can generate said JSON, I’ll paste in the script and talk about the final task 2 JSON
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
#!/usr/bin/env python3
"""
disasm_exports.py
Parse a DLL's export table, print exports, and disassemble the first N instructions
of each exported function using Capstone.
Requires:
pip install pefile capstone
"""
import json
import argparse
import sys
from capstone import Cs, CS_ARCH_X86, CS_MODE_32, CS_MODE_64
import pefile
# Global configuration for minimal instructions needed per class
MINIMAL_DISASSEMBLE_CLASS = {
'B': 85, # Adjust based on your actual needs
'C': 30, # Adjust based on your actual needs
'D': 22 # Adjust based on your actual needs
}
# Initial disassembly count just to identify function class
INITIAL_DISASM_COUNT = 10
# Check parsing
CHECK_BYTES_NUM = 0x6000
check_func_obj = dict()
MEMCMP_SEQ = b"\x48\x89\x85\x00\x01\x00\x00\x48\x89\x95\x08\x01\x00\x00\x48\x8D\x95\x10\x03\x00\x00\x48\x8D\x45\x10\x41\xB8\x00\x01\x00\x00\x48\x89\xC1"
AFTER_F_CHAIN_SEQ = b"\xBA\x00\x00\x00\x00\x48\x89\x85\x00\x05\x00\x00\x48\x89\x95\x08\x05\x00\x00\xC7\x85\x7C\x05\x00\x00\x00\x00\x00\x00\xE9\xD8\x00\x00\x00"
MEMCMP_REL_OFF = -0x198
AFTER_F_CHAIN_REL_OFF = -0x1eb
MEMCMP_DISASS = (80, 500)
AFTER_F_CHAIN_DISASS = (80, 600)
def detect_cs_mode(pe):
# IMAGE_FILE_MACHINE_AMD64 = 0x8664, IMAGE_FILE_MACHINE_I386 = 0x14c
machine = getattr(pe.FILE_HEADER, "Machine", None)
if machine is None:
raise RuntimeError("Cannot determine PE machine type")
if machine == 0x8664:
return CS_MODE_64
elif machine == 0x14c:
return CS_MODE_32
else:
raise RuntimeError(f"Unsupported machine type: 0x{machine:04x}")
def safe_decode(b):
if b is None:
return None
if isinstance(b, str):
return b
try:
return b.decode('utf-8', errors='replace')
except Exception:
return str(b)
def disasm_bytes(cs, data, start_va, count):
"""
Disassemble up to `count` instructions from `data` starting at virtual address start_va.
Returns a list of (address, mnemonic, op_str) tuples.
"""
out = []
for insn in cs.disasm(data, start_va):
out.append((insn.address, insn.mnemonic, insn.op_str))
if len(out) >= count:
break
return out
def parse_movabs(insts):
movabs = []
for x in insts:
if x[1] == 'movabs':
movabs.append(x[2])
vals = [x[x.index('0x'):] for x in movabs]
return vals
def parse_B_function(insts):
movabs_vals = parse_movabs(insts)
return movabs_vals
def parse_C_function(insts):
movabs_vals = parse_movabs(insts)
movabs_vals = movabs_vals[:4]
return movabs_vals
def parse_D_function(insts):
movabs_vals = parse_movabs(insts)
movabs_vals = movabs_vals[:4]
return movabs_vals
def parse_check_function(insts, md):
MEMCMP_DISASM_COUNT = MEMCMP_DISASS[0]
AFTER_F_CHAIN_DISASM_COUNT = AFTER_F_CHAIN_DISASS[0]
data = check_func_obj['data']
# Find and extract memcmp data
memcmp_ptr = data.find(MEMCMP_SEQ)
if memcmp_ptr == -1:
raise ValueError("Could not find MEMCMP_SEQ")
memcmp_ptr += MEMCMP_REL_OFF
memcmp_data = data[memcmp_ptr:memcmp_ptr + MEMCMP_DISASS[1]]
if not memcmp_data:
raise ValueError("No memcmp data at computed offset")
# Find and extract after_f_chain data
after_f_chain_ptr = data.find(AFTER_F_CHAIN_SEQ)
if after_f_chain_ptr == -1:
raise ValueError("Could not find AFTER_F_CHAIN_SEQ")
after_f_chain_ptr += AFTER_F_CHAIN_REL_OFF
after_f_chain_data = data[after_f_chain_ptr:after_f_chain_ptr + AFTER_F_CHAIN_DISASS[1]]
if not after_f_chain_data:
raise ValueError("No after_f_chain data at computed offset")
# Disassemble both sections
memcmp_insns = disasm_bytes(md, memcmp_data, MEMCMP_DISASS[0], MEMCMP_DISASM_COUNT)
after_f_chain_insns = disasm_bytes(md, after_f_chain_data, AFTER_F_CHAIN_DISASS[0], AFTER_F_CHAIN_DISASM_COUNT)
# Parse movabs instructions
movabs_memcmp = parse_movabs(memcmp_insns)
movabs_after_f_chain = parse_movabs(after_f_chain_insns)
# Return or process the parsed data
return {
'memcmp': movabs_memcmp,
'after_f_chain': movabs_after_f_chain
}
#raise NotImplementedError
demangle_f = lambda f_name: f_name[4:25]
def main():
ap = argparse.ArgumentParser(description="List DLL exports and disassemble first N instructions using Capstone")
ap.add_argument("pefile", help="Path to PE/DLL file")
ap.add_argument("-n", "--instructions", type=int, default=8, help="Number of instructions to disassemble per export (default: 8)")
ap.add_argument("--max-bytes", type=int, default=256, help="Max bytes to read per exported function (default: 256)")
ap.add_argument("--raw-addr", action="store_true", help="Print raw file offset instead of virtual address")
args = ap.parse_args()
path = args.pefile
exported_funcs = []
classes_prologue = { 'rsp, 0x110':'B', 'rsp, 0xc0':'C', 'rsp, 0x50':'D', 'rsp, 0x608':'check' }
db = dict()
try:
pe = pefile.PE(path, fast_load=True)
# load directories needed
pe.parse_data_directories(directories=[pefile.DIRECTORY_ENTRY['IMAGE_DIRECTORY_ENTRY_EXPORT']])
except FileNotFoundError:
print(f"File not found: {path}", file=sys.stderr)
sys.exit(1)
except pefile.PEFormatError as e:
print(f"PEFormatError: {e}", file=sys.stderr)
sys.exit(1)
# Read raw file bytes for slicing
with open(path, "rb") as f:
raw = f.read()
try:
mode = detect_cs_mode(pe)
except RuntimeError as e:
print("Error:", e, file=sys.stderr)
sys.exit(1)
md = Cs(CS_ARCH_X86, mode)
md.detail = False
image_base = getattr(pe.OPTIONAL_HEADER, "ImageBase", 0)
if not hasattr(pe, "DIRECTORY_ENTRY_EXPORT"):
print("No export directory found.")
return
symbols = pe.DIRECTORY_ENTRY_EXPORT.symbols
if not symbols:
print("No exported symbols found.")
return
for sym in symbols:
name = safe_decode(sym.name) or f"<ordinal_{sym.ordinal}>"
forwarder = getattr(sym, "forwarder", None)
if forwarder:
forwarder_str = safe_decode(forwarder)
else:
forwarder_str = None
if name.find('_Z21f') != 0 and name != '_Z5checkPh':
continue
rva = getattr(sym, "address", None)
# Some entries may have address==0 or be forwarded. Handle both.
if forwarder_str:
print(f" -> Forwarded to: {forwarder_str}")
print("-" * 60)
continue
if rva is None:
print(" -> No address information; skipping.")
print("-" * 60)
continue
va = image_base + rva
# Attempt to convert RVA to file offset
try:
file_offset = pe.get_offset_from_rva(rva)
except Exception as e:
print(f" -> get_offset_from_rva failed for rva 0x{rva:x}: {e}")
print("-" * 60)
continue
if file_offset < 0 or file_offset >= len(raw):
print(f" -> File offset out of range (offset=0x{file_offset:x}, file_size=0x{len(raw):x}). Skipping.")
print("-" * 60)
continue
max_bytes = 510 if name != '_Z5checkPh' else CHECK_BYTES_NUM
data = raw[file_offset:file_offset + max_bytes]
if not data:
print(" -> No data at computed offset; skipping.")
print("-" * 60)
continue
# Stage 1: Disassemble minimal instructions to identify function class
initial_insns = disasm_bytes(md, data, va, INITIAL_DISASM_COUNT)
# If check, add bytes
check_func_obj['data'] = data
# Find the function class
sub_ind = -1
for i, x in enumerate(initial_insns):
if x[1] == 'sub':
sub_ind = i
break
if sub_ind == -1:
print(f" -> Could not identify function class for {name}; skipping.")
continue
stack_frame_size = initial_insns[sub_ind][2]
if stack_frame_size not in classes_prologue:
print(f" -> Unknown stack frame size {stack_frame_size} for {name}; skipping.")
continue
class_type = classes_prologue[stack_frame_size]
# Stage 2: Disassemble only the required number of instructions for this class
required_insns = MINIMAL_DISASSEMBLE_CLASS.get(class_type, 20)
insns = disasm_bytes(md, data, va, required_insns)
exported_funcs.append((name, va, insns, class_type))
for f in exported_funcs:
try:
name, va, insts, class_type = f
demangled_name = demangle_f(name)
func_consts = None
if class_type == 'B':
func_consts = parse_B_function(insts)
elif class_type == 'C':
func_consts = parse_C_function(insts)
elif class_type == 'D':
func_consts = parse_D_function(insts)
elif class_type == 'check':
func_consts = parse_check_function(insts, md)
else:
print('unknown function: {}'.format(name))
continue
key_name = 'check' if name == '_Z5checkPh' else demangled_name
db[key_name] = { 'class': class_type, 'consts': func_consts }
except NotImplementedError:
print('Not implemented for function: {}'.format(f[0]))
continue
except Exception as e:
print('Error in function: {} - {}'.format(f[0], str(e)))
continue
# Write the database once at the end
with open(args.pefile + '.json', 'w+') as jf:
json.dump(db, jf, indent=4)
if __name__ == "__main__":
main()
And the JSON:
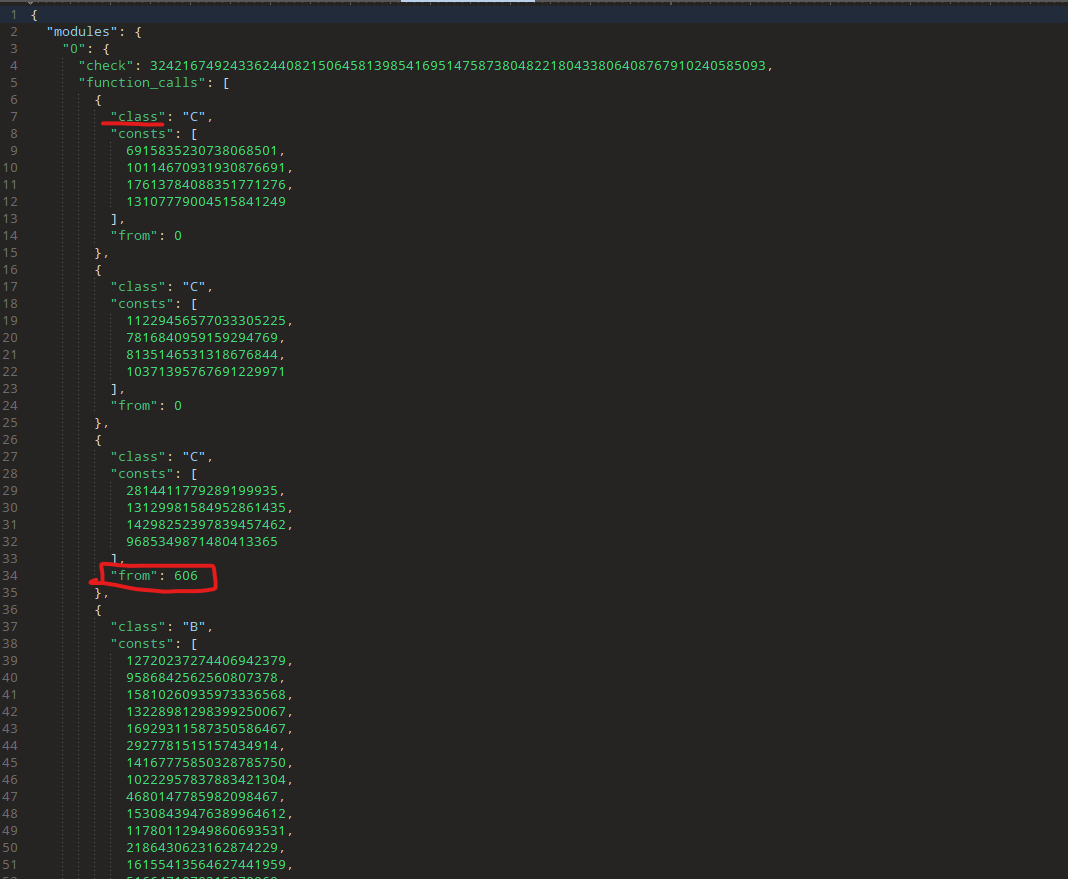
Each module has a list of sorted function calls (all the fs in order) and all of their types, constants and their parent-module (for grabbing the right state[resource_id]). Now we can combine this with the f reversing logic, together with the final JSON from task 1 to generate one final license.
Integration
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
import json
import struct
import time
from typing import Tuple, Union, Optional
import os, random, binascii
import secrets
import argparse
class TransformPipeline:
"""Wrapper for chaining transformations on license data."""
def __init__(self, data: bytes):
if not isinstance(data, bytes):
raise ValueError("data must be bytes")
if len(data) != 32:
raise ValueError("data must be exactly 32 bytes")
self._data = data
@property
def result(self) -> bytes:
"""Get the final result."""
return self._data
def funcb_forward(self, funcb: 'FuncB', glob_block: int) -> 'TransformPipeline':
"""Apply FuncB forward transformation."""
self._data = funcb.forward(self._data, glob_block)
return self
def funcb_reverse(self, funcb: 'FuncB', glob_block: int) -> 'TransformPipeline':
"""Apply FuncB reverse transformation."""
self._data = funcb.reverse(self._data, glob_block)
return self
def funcc_forward(self, funcc: 'FuncC', glob_block: int) -> 'TransformPipeline':
"""Apply FuncC forward transformation."""
self._data = funcc.forward(self._data, glob_block)
return self
def funcc_reverse(self, funcc: 'FuncC', glob_block: int) -> 'TransformPipeline':
"""Apply FuncC reverse transformation (returns first valid result)."""
result = funcc.reverse(self._data, glob_block)
if isinstance(result, tuple):
if result[0] is not None:
self._data = result[0]
else:
raise ValueError(f"FuncC reverse failed: {result[1]}")
else:
self._data = result
return self
def funcd_reverse(self, funcd: 'FuncD', glob_block: int) -> 'TransformPipeline':
"""Apply FuncD reverse transformation."""
self._data = funcd.reverse(self._data, glob_block)
return self
def funcb_set_consts(self, funcb: 'FuncB', const_arr: list) -> 'TransformPipeline':
"""Set constants for FuncB instance."""
funcb.set_consts(const_arr)
return self
def funcc_set_consts(self, funcc: 'FuncC', locBuf: list) -> 'TransformPipeline':
"""Set constants for FuncC instance."""
funcc.set_consts(locBuf)
return self
def funcd_set_consts(self, funcd: 'FuncD', qwords: list) -> 'TransformPipeline':
"""Set constants for FuncD instance."""
funcd.set_consts(qwords)
return self
def __bytes__(self) -> bytes:
"""Allow using bytes(pipeline) to get result."""
return self._data
def __repr__(self) -> str:
return f"TransformPipeline({self._data.hex()})"
class FuncB:
def __init__(self, const_arr):
self.set_consts(const_arr)
def set_consts(self, const_arr):
"""Set or update the constant array and rebuild tables."""
self.const_arr = const_arr
# Mask to 64 bits and build SUB_TABLE
masked_arr = [q & 0xFFFFFFFFFFFFFFFF for q in const_arr]
self.SUB_TABLE = b''.join(q.to_bytes(8, 'little') for q in masked_arr)
assert len(self.SUB_TABLE) == 256
# Build inverse table and ensure bijection
self.INV = [-1]*256
for i, b in enumerate(self.SUB_TABLE):
if self.INV[b] != -1:
raise ValueError(f"SUB_TABLE not bijection: byte {b:02x} appears twice at indices {self.INV[b]} and {i}")
self.INV[b] = i
if any(x == -1 for x in self.INV):
missing = [i for i,x in enumerate(self.INV) if x == -1]
raise ValueError(f"SUB_TABLE not bijection: missing outputs for bytes {missing[:10]}...")
def forward(self, licData: bytes, globBlock: int) -> bytes:
...
def reverse(self, outData: bytes, globBlock: int) -> bytes:
"""
Reverse transformation.
outData: 32-byte transformed data (output of forward).
globBlock: same 32-bit integer used in forward.
Returns original 32-byte licData.
"""
if len(outData) != 32:
raise ValueError("outData must be exactly 32 bytes")
temp = bytearray(32)
for i in range(32):
temp[i] = self.INV[outData[i]]
# undo XOR on first 4 bytes
v = int.from_bytes(temp[0:4], 'little') ^ (globBlock & 0xFFFFFFFF)
temp[0:4] = v.to_bytes(4, 'little')
return bytes(temp)
class FuncC:
LIC_SIZE = 32
MOD = 256 ** LIC_SIZE
LAMBDA = 2 ** 254
@staticmethod
def build_locbuf(qwords: list[int]) -> bytearray:
"""Reproduce exact overlapping writes from the assembly."""
buf = bytearray(32)
# Mask each qword to 64 bits
masked = [q & 0xFFFFFFFFFFFFFFFF for q in qwords]
buf[0:8] = masked[0].to_bytes(8, "little")
buf[8:16] = masked[1].to_bytes(8, "little")
buf[0x0F:0x0F+8] = masked[2].to_bytes(8, "little")
buf[0x17:0x17+8] = masked[3].to_bytes(8, "little")
return buf
def __init__(self, locBuf: list[int]):
self.set_consts(locBuf)
def set_consts(self, locBuf: list[int]):
"""Set or update the location buffer constants."""
self.LOCBUF = FuncC.build_locbuf(locBuf)
@staticmethod
def le_bytes_to_int(b: bytes) -> int:
"""Convert little-endian bytes to integer."""
return int.from_bytes(b, "little")
@staticmethod
def int_to_le_bytes(v: int, length: int = 32) -> bytes:
"""Convert integer to little-endian bytes."""
return (v % FuncC.MOD).to_bytes(length, "little")
def forward(self, lic_in: bytes, glob_dword: int) -> bytes:
...
# XOR low dword with glob value (write full dword)
orig_dword = int.from_bytes(mem[0:4], "little")
new_dword = (orig_dword ^ (glob_dword & 0xFFFFFFFF)) & 0xFFFFFFFF
mem[0:4] = new_dword.to_bytes(4, "little")
# var_31 = low byte & 1 (after XOR)
var_31 = mem[0] & 1
# write low byte = low_byte | 1 (assembly writes one byte only)
mem[0] = mem[0] | 1
# base (32-byte little-endian int)
base = FuncC.le_bytes_to_int(bytes(mem))
acc = 1
# build exponent integer from first 31 bytes of locBuf (0..0x1E)
exponent_int = 0
for byte_index in range(0x1F): # 31 bytes = 248 bits
exponent_int |= self.LOCBUF[byte_index] << (8 * byte_index)
# iterate bits little-endian (low bit first)
for bit_index in range(0x1F * 8): # 248 bits
bit = (exponent_int >> bit_index) & 1
if bit:
acc = (acc * base) % self.MOD
base = (base * base) % self.MOD
# write acc back (32 bytes)
acc_bytes = FuncC.int_to_le_bytes(acc, self.LIC_SIZE)
result = bytearray(acc_bytes)
# final low byte tweak: result[0] = (result[0] ^ var_31) ^ 1
result[0] = ((result[0] ^ var_31) ^ 1) & 0xFF
return bytes(result)
@staticmethod
def modinv_odd_exponent(e: int) -> Optional[int]:
"""Return inverse of e modulo LAMBDA (2^254) if it exists (i.e. e odd)."""
if e % 2 == 0:
return None
try:
return pow(e, -1, FuncC.LAMBDA)
except TypeError:
# fallback (rare): extended gcd
def egcd(a, b):
if b == 0:
return (1, 0, a)
x1, y1, g = egcd(b, a % b)
return (y1, x1 - (a // b) * y1, g)
inv, _, g = egcd(e, FuncC.LAMBDA)
if g != 1:
return None
return inv % FuncC.LAMBDA
def reverse(self, output_bytes: bytes, glob_dword: int) -> Tuple[Optional[bytes], str]:
"""
Attempt to recover original lic_in from final output and glob_dword.
Returns (original_bytes or None, message).
"""
assert len(output_bytes) == self.LIC_SIZE
out = bytearray(output_bytes)
exponent_int = 0
for byte_index in range(0x1F):
exponent_int |= self.LOCBUF[byte_index] << (8 * byte_index)
if exponent_int % 2 == 0:
return None, "Exponent is even -> no modular inverse; cannot invert."
d = FuncC.modinv_odd_exponent(exponent_int)
if d is None:
return None, "Exponent inverse doesn't exist (gcd != 1)."
for var31 in (0, 1):
# undo final low-byte tweak
acc0 = ((out[0] ^ 1) ^ var31) & 0xFF
acc_bytes = bytearray(out)
acc_bytes[0] = acc0
acc_int = FuncC.le_bytes_to_int(bytes(acc_bytes))
# base = acc^d mod 2^256
base_int = pow(acc_int, d, self.MOD)
base_bytes = FuncC.int_to_le_bytes(base_int, self.LIC_SIZE)
# base must have LSB==1 because assembly set it before exponentiation
if (base_bytes[0] & 1) == 0:
continue
# reconstruct Y (value after XOR but before low-byte OR):
if var31 == 1:
y0 = base_bytes[0]
else:
y0 = base_bytes[0] & (~1)
y_bytes = bytes([y0]) + base_bytes[1:4]
new_dword = int.from_bytes(y_bytes, "little")
orig_dword = new_dword ^ (glob_dword & 0xFFFFFFFF)
# reconstruct candidate original lic: low dword = orig_dword, rest = base_bytes[4:]
candidate = bytearray(self.LIC_SIZE)
candidate[0:4] = orig_dword.to_bytes(4, "little")
candidate[4:] = base_bytes[4:]
# verify by running forward
if self.forward(bytes(candidate), glob_dword) == bytes(out):
return bytes(candidate)
return None, "No valid preimage found (both var_31 candidates failed)."
class FuncD:
@staticmethod
def build_table(qwords: list[int]) -> bytes:
"""Build permutation table from 4 qwords."""
if len(qwords) != 4:
raise ValueError(f"Expected 4 qwords, got {len(qwords)}")
IMM1, IMM2, IMM3, IMM4 = qwords
table = bytearray()
for imm in (IMM1, IMM2, IMM3, IMM4):
# Mask to 64 bits to prevent overflow
masked_imm = imm & 0xFFFFFFFFFFFFFFFF
table += masked_imm.to_bytes(8, 'little')
if len(table) != 32:
raise RuntimeError("table length != 32")
return bytes(table)
def __init__(self, qwords: list[int]):
self.set_consts(qwords)
def set_consts(self, qwords: list[int]):
"""Set or update the permutation table constants."""
self.table = FuncD.build_table(qwords)
def forward(self, licData: bytes, globBlock: int) -> bytes:
...
def reverse(self, out32: bytes, glob: Union[bytes, int]) -> bytes:
"""
Reverse transformation using permutation table.
Args:
out32: 32-byte transformed output
glob: 4-byte glob value (bytes or int)
Returns:
Original 32-byte license data
"""
if not isinstance(out32, (bytes, bytearray)) or len(out32) != 32:
raise ValueError("out32 must be 32 bytes")
# Normalize glob to 4-byte int (little-endian)
if isinstance(glob, (bytes, bytearray)):
if len(glob) != 4:
raise ValueError("glob must be 4 bytes")
glob_val = int.from_bytes(glob, 'little')
elif isinstance(glob, int):
glob_val = glob & 0xFFFFFFFF
else:
raise ValueError("glob must be bytes or int")
# Build inverse permutation table
inv = [-1] * 32
for i, t in enumerate(self.table):
if t < 0 or t >= 32:
raise ValueError(f"table value out of range: {t} at index {i}")
if inv[t] != -1:
raise ValueError(f"table is not a permutation (duplicate {t})")
inv[t] = i
if any(x == -1 for x in inv):
raise ValueError("table is not a full permutation of 0..31")
# Apply inverse permutation
temp = bytearray(32)
for pos in range(32):
temp[pos] = out32[inv[pos]]
# Undo XOR on first 4 bytes
temp0_uint32 = int.from_bytes(temp[0:4], 'little')
orig0_uint32 = temp0_uint32 ^ glob_val
temp[0:4] = orig0_uint32.to_bytes(4, 'little')
return bytes(temp)
def main():
ap = argparse.ArgumentParser()
ap.add_argument('--state', required=True)
ap.add_argument('--layers', required=True)
ap.add_argument('--license', default='license.bin')
args = ap.parse_args()
start_time = time.time()
N = 10000
print('[+] Opening all files and parsing jsons...')
state_file = open(args.state, 'r')
layers_file = open(args.layers, 'r')
layers = json.load(layers_file)['modules']
license = open(args.license, 'wb')
current_time = time.time()
last_global = None
print(f'[+] All files parsed in: {current_time - start_time}')
print('[+] Starting reversing of license.bin according to load order...')
for i in range(N):
current_state = json.loads(state_file.readline())
current_module = str(current_state['module'])
current_global = last_global
check_out = layers[current_module]['check'].to_bytes(32, 'little')
for func in layers[current_module]['function_calls']:
from_id = func['from']
dword = current_global[from_id] if i > 0 else 0
consts = func['consts']
func_type = func['class']
if func_type == 'B':
func_object = FuncB(consts)
elif func_type == 'C':
func_object = FuncC(consts)
elif func_type == 'D':
func_object = FuncD(consts)
check_out = func_object.reverse(check_out, dword)
if i == 1:
breakpoint()
license.write(struct.pack('<H', int(current_module)) + check_out)
if i % 100 == 0:
current_time = time.time()
print(f'\t[+] Iteration {i} Total time {current_time - start_time}')
last_global = current_state['global']
current_time = time.time()
print(f'[+] Finished!!! Runtime -> {current_time - start_time}')
if __name__ == '__main__':
main()
Snippet from the output:
Giant Win
Now running the program until a breakpoint before the huge loop 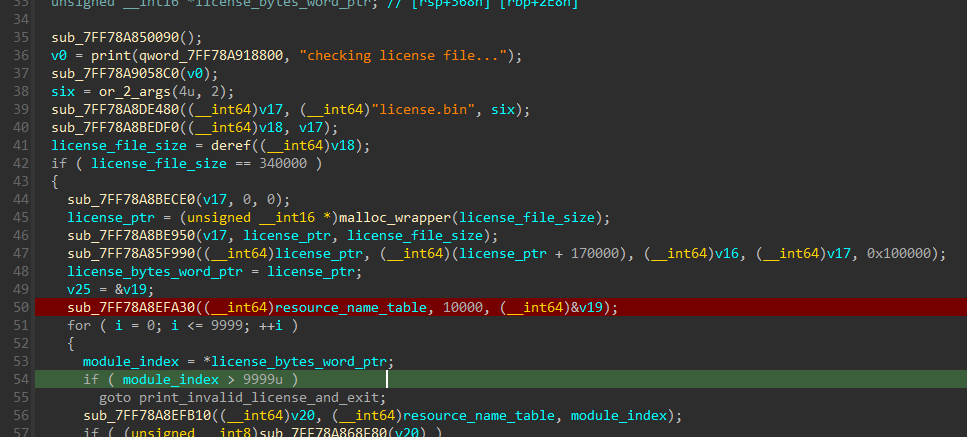
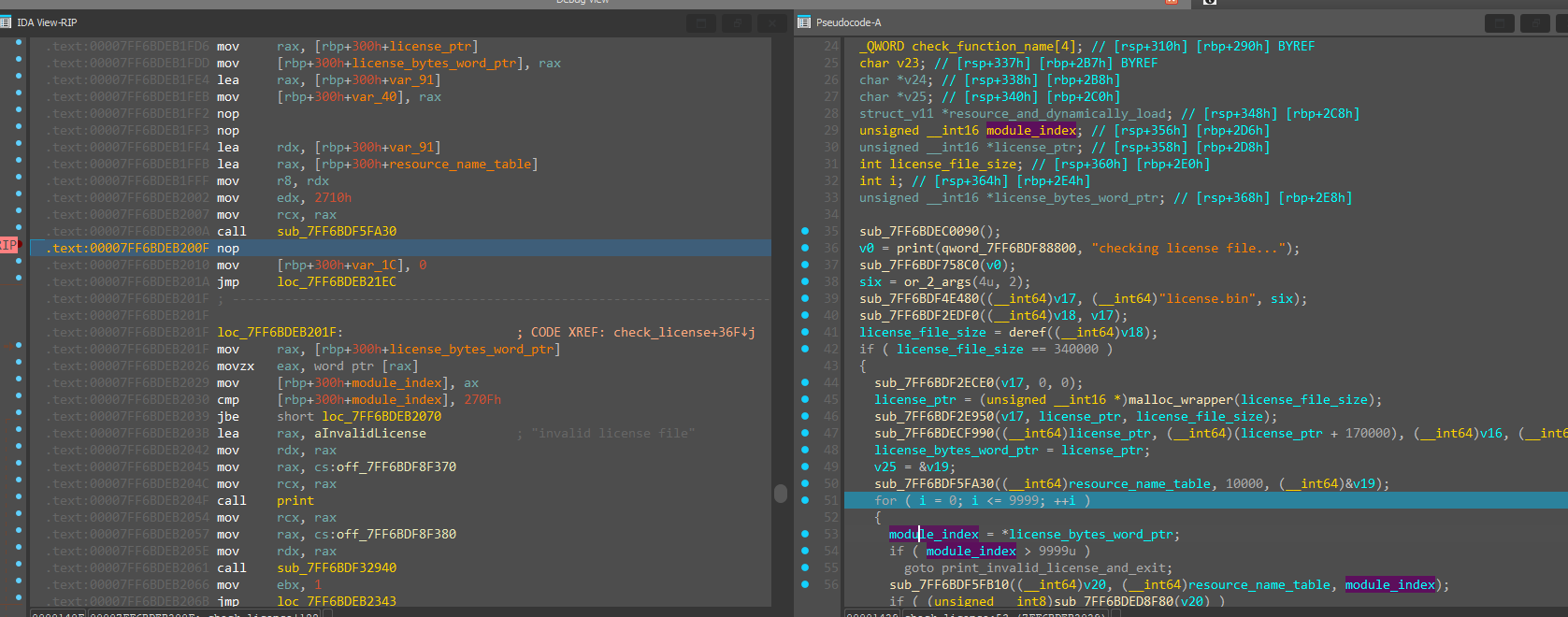
Changing RIP to be after the memcmp:
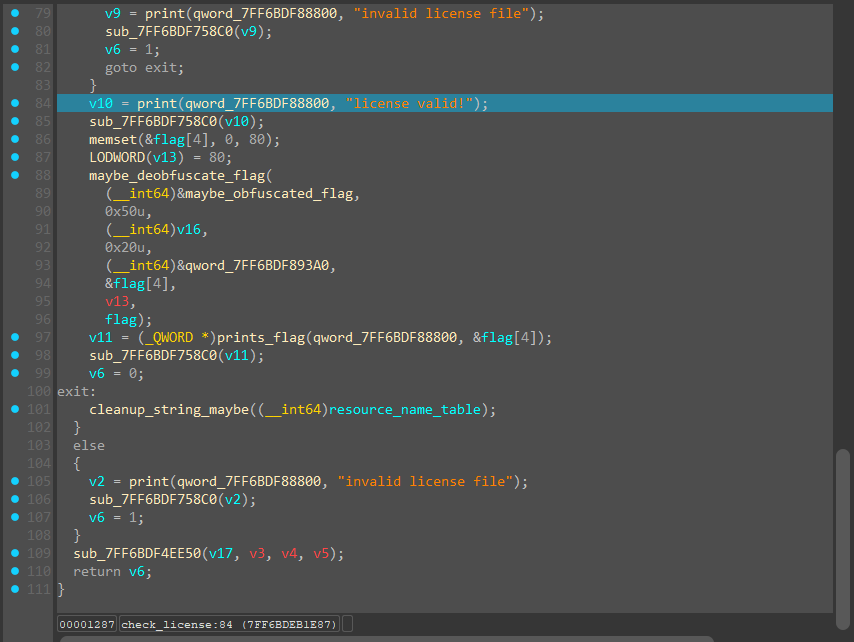
And for the final time this year, continuing.